Compare commits
22 Commits
dependabot
...
state_as_f
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
302e3b7973 | ||
|
|
b6cb93fca0 | ||
|
|
3ac7c9c80a | ||
|
|
9c3a585915 | ||
|
|
e6569653b1 | ||
|
|
9e31fe65ce | ||
|
|
572f1d8bdb | ||
|
|
26935af4b6 | ||
|
|
c58fd41f46 | ||
|
|
119726d986 | ||
|
|
23f319bb40 | ||
|
|
126bbc6970 | ||
|
|
849a54ef2d | ||
|
|
f1dd728413 | ||
|
|
9a064b78e6 | ||
|
|
92ea89e59a | ||
|
|
77232fa68e | ||
|
|
cfdbc8bd23 | ||
|
|
64978b45fe | ||
|
|
97e8ea219b | ||
|
|
cf239c1232 | ||
|
|
613996dd01 |
@@ -1,9 +0,0 @@
|
||||
.env
|
||||
Dockerfile
|
||||
/characters
|
||||
/loras
|
||||
/models
|
||||
/presets
|
||||
/prompts
|
||||
/softprompts
|
||||
/training
|
||||
25
.env.example
25
.env.example
@@ -1,25 +0,0 @@
|
||||
# by default the Dockerfile specifies these versions: 3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX
|
||||
# however for me to work i had to specify the exact version for my card ( 2060 ) it was 7.5
|
||||
# https://developer.nvidia.com/cuda-gpus you can find the version for your card here
|
||||
TORCH_CUDA_ARCH_LIST=7.5
|
||||
|
||||
# these commands worked for me with roughly 4.5GB of vram
|
||||
CLI_ARGS=--model llama-7b-4bit --wbits 4 --listen --auto-devices
|
||||
|
||||
# the following examples have been tested with the files linked in docs/README_docker.md:
|
||||
# example running 13b with 4bit/128 groupsize : CLI_ARGS=--model llama-13b-4bit-128g --wbits 4 --listen --groupsize 128 --pre_layer 25
|
||||
# example with loading api extension and public share: CLI_ARGS=--model llama-7b-4bit --wbits 4 --listen --auto-devices --no-stream --extensions api --share
|
||||
# example running 7b with 8bit groupsize : CLI_ARGS=--model llama-7b --load-in-8bit --listen --auto-devices
|
||||
|
||||
# the port the webui binds to on the host
|
||||
HOST_PORT=7860
|
||||
# the port the webui binds to inside the container
|
||||
CONTAINER_PORT=7860
|
||||
|
||||
# the port the api binds to on the host
|
||||
HOST_API_PORT=5000
|
||||
# the port the api binds to inside the container
|
||||
CONTAINER_API_PORT=5000
|
||||
|
||||
# the version used to install text-generation-webui from
|
||||
WEBUI_VERSION=HEAD
|
||||
68
Dockerfile
68
Dockerfile
@@ -1,68 +0,0 @@
|
||||
FROM nvidia/cuda:11.8.0-devel-ubuntu22.04 as builder
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get install --no-install-recommends -y git vim build-essential python3-dev python3-venv && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN git clone https://github.com/oobabooga/GPTQ-for-LLaMa /build
|
||||
|
||||
WORKDIR /build
|
||||
|
||||
RUN python3 -m venv /build/venv
|
||||
RUN . /build/venv/bin/activate && \
|
||||
pip3 install --upgrade pip setuptools && \
|
||||
pip3 install torch torchvision torchaudio && \
|
||||
pip3 install -r requirements.txt
|
||||
|
||||
# https://developer.nvidia.com/cuda-gpus
|
||||
# for a rtx 2060: ARG TORCH_CUDA_ARCH_LIST="7.5"
|
||||
ARG TORCH_CUDA_ARCH_LIST="3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX"
|
||||
RUN . /build/venv/bin/activate && \
|
||||
python3 setup_cuda.py bdist_wheel -d .
|
||||
|
||||
FROM nvidia/cuda:11.8.0-runtime-ubuntu22.04
|
||||
|
||||
LABEL maintainer="Your Name <your.email@example.com>"
|
||||
LABEL description="Docker image for GPTQ-for-LLaMa and Text Generation WebUI"
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get install --no-install-recommends -y git python3 python3-pip make g++ && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN --mount=type=cache,target=/root/.cache/pip pip3 install virtualenv
|
||||
RUN mkdir /app
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
ARG WEBUI_VERSION
|
||||
RUN test -n "${WEBUI_VERSION}" && git reset --hard ${WEBUI_VERSION} || echo "Using provided webui source"
|
||||
|
||||
RUN virtualenv /app/venv
|
||||
RUN . /app/venv/bin/activate && \
|
||||
pip3 install --upgrade pip setuptools && \
|
||||
pip3 install torch torchvision torchaudio
|
||||
|
||||
COPY --from=builder /build /app/repositories/GPTQ-for-LLaMa
|
||||
RUN . /app/venv/bin/activate && \
|
||||
pip3 install /app/repositories/GPTQ-for-LLaMa/*.whl
|
||||
|
||||
COPY extensions/api/requirements.txt /app/extensions/api/requirements.txt
|
||||
COPY extensions/elevenlabs_tts/requirements.txt /app/extensions/elevenlabs_tts/requirements.txt
|
||||
COPY extensions/google_translate/requirements.txt /app/extensions/google_translate/requirements.txt
|
||||
COPY extensions/silero_tts/requirements.txt /app/extensions/silero_tts/requirements.txt
|
||||
COPY extensions/whisper_stt/requirements.txt /app/extensions/whisper_stt/requirements.txt
|
||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/api && pip3 install -r requirements.txt
|
||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/elevenlabs_tts && pip3 install -r requirements.txt
|
||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/google_translate && pip3 install -r requirements.txt
|
||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/silero_tts && pip3 install -r requirements.txt
|
||||
RUN --mount=type=cache,target=/root/.cache/pip . /app/venv/bin/activate && cd extensions/whisper_stt && pip3 install -r requirements.txt
|
||||
|
||||
COPY requirements.txt /app/requirements.txt
|
||||
RUN . /app/venv/bin/activate && \
|
||||
pip3 install -r requirements.txt
|
||||
|
||||
RUN cp /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda118.so /app/venv/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cpu.so
|
||||
|
||||
COPY . /app/
|
||||
ENV CLI_ARGS=""
|
||||
CMD . /app/venv/bin/activate && python3 server.py ${CLI_ARGS}
|
||||
142
README.md
142
README.md
@@ -1,9 +1,11 @@
|
||||
# Text generation web UI
|
||||
|
||||
A gradio web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and GALACTICA.
|
||||
A gradio web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, OPT, and GALACTICA.
|
||||
|
||||
Its goal is to become the [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) of text generation.
|
||||
|
||||
[[Try it on Google Colab]](https://colab.research.google.com/github/oobabooga/AI-Notebooks/blob/main/Colab-TextGen-GPU.ipynb)
|
||||
|
||||
| |  |
|
||||
|:---:|:---:|
|
||||
| |  |
|
||||
@@ -13,7 +15,6 @@ Its goal is to become the [AUTOMATIC1111/stable-diffusion-webui](https://github.
|
||||
* Dropdown menu for switching between models
|
||||
* Notebook mode that resembles OpenAI's playground
|
||||
* Chat mode for conversation and role playing
|
||||
* Instruct mode compatible with Alpaca and Open Assistant formats **\*NEW!\***
|
||||
* Nice HTML output for GPT-4chan
|
||||
* Markdown output for [GALACTICA](https://github.com/paperswithcode/galai), including LaTeX rendering
|
||||
* [Custom chat characters](https://github.com/oobabooga/text-generation-webui/wiki/Custom-chat-characters)
|
||||
@@ -29,9 +30,10 @@ Its goal is to become the [AUTOMATIC1111/stable-diffusion-webui](https://github.
|
||||
* [LLaMA model, including 4-bit GPTQ](https://github.com/oobabooga/text-generation-webui/wiki/LLaMA-model)
|
||||
* [llama.cpp](https://github.com/oobabooga/text-generation-webui/wiki/llama.cpp-models) **\*NEW!\***
|
||||
* [RWKV model](https://github.com/oobabooga/text-generation-webui/wiki/RWKV-model)
|
||||
* [LoRA (loading and training)](https://github.com/oobabooga/text-generation-webui/wiki/Using-LoRAs)
|
||||
* [LoRa (loading and training)](https://github.com/oobabooga/text-generation-webui/wiki/Using-LoRAs)
|
||||
* Softprompts
|
||||
* [Extensions](https://github.com/oobabooga/text-generation-webui/wiki/Extensions)
|
||||
* [Google Colab](https://github.com/oobabooga/text-generation-webui/wiki/Running-on-Colab)
|
||||
|
||||
## Installation
|
||||
|
||||
@@ -70,15 +72,9 @@ On Linux or WSL, it can be automatically installed with these two commands:
|
||||
curl -sL "https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh" > "Miniconda3.sh"
|
||||
bash Miniconda3.sh
|
||||
```
|
||||
|
||||
Source: https://educe-ubc.github.io/conda.html
|
||||
|
||||
#### 0.1 (Ubuntu/WSL) Install build tools
|
||||
|
||||
```
|
||||
sudo apt install build-essential
|
||||
```
|
||||
|
||||
|
||||
#### 1. Create a new conda environment
|
||||
|
||||
```
|
||||
@@ -120,26 +116,8 @@ As an alternative to the recommended WSL method, you can install the web UI nati
|
||||
|
||||
### Alternative: Docker
|
||||
|
||||
```
|
||||
cp .env.example .env
|
||||
docker compose up --build
|
||||
```
|
||||
https://github.com/oobabooga/text-generation-webui/issues/174, https://github.com/oobabooga/text-generation-webui/issues/87
|
||||
|
||||
Make sure to edit `.env.example` and set the appropriate CUDA version for your GPU.
|
||||
|
||||
You need to have docker compose v2.17 or higher installed in your system. For installation instructions, see [Docker compose installation](https://github.com/oobabooga/text-generation-webui/wiki/Docker-compose-installation).
|
||||
|
||||
Contributed by [@loeken](https://github.com/loeken) in [#633](https://github.com/oobabooga/text-generation-webui/pull/633)
|
||||
|
||||
### Updating the requirements
|
||||
|
||||
From time to time, the `requirements.txt` changes. To update, use this command:
|
||||
|
||||
```
|
||||
conda activate textgen
|
||||
cd text-generation-webui
|
||||
pip install -r requirements.txt --upgrade
|
||||
```
|
||||
## Downloading models
|
||||
|
||||
Models should be placed inside the `models` folder.
|
||||
@@ -194,84 +172,82 @@ Optionally, you can use the following command-line flags:
|
||||
|
||||
#### Basic settings
|
||||
|
||||
| Flag | Description |
|
||||
|--------------------------------------------|-------------|
|
||||
| `-h`, `--help` | Show this help message and exit. |
|
||||
| `--notebook` | Launch the web UI in notebook mode, where the output is written to the same text box as the input. |
|
||||
| `--chat` | Launch the web UI in chat mode. |
|
||||
| `--model MODEL` | Name of the model to load by default. |
|
||||
| `--lora LORA` | Name of the LoRA to apply to the model by default. |
|
||||
| `--model-dir MODEL_DIR` | Path to directory with all the models. |
|
||||
| `--lora-dir LORA_DIR` | Path to directory with all the loras. |
|
||||
| `--no-stream` | Don't stream the text output in real time. |
|
||||
| `--settings SETTINGS_FILE` | Load the default interface settings from this json file. See `settings-template.json` for an example. If you create a file called `settings.json`, this file will be loaded by default without the need to use the `--settings` flag. |
|
||||
| `--extensions EXTENSIONS [EXTENSIONS ...]` | The list of extensions to load. If you want to load more than one extension, write the names separated by spaces. |
|
||||
| `--verbose` | Print the prompts to the terminal. |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `-h`, `--help` | show this help message and exit |
|
||||
| `--notebook` | Launch the web UI in notebook mode, where the output is written to the same text box as the input. |
|
||||
| `--chat` | Launch the web UI in chat mode.|
|
||||
| `--model MODEL` | Name of the model to load by default. |
|
||||
| `--lora LORA` | Name of the LoRA to apply to the model by default. |
|
||||
| `--model-dir MODEL_DIR` | Path to directory with all the models |
|
||||
| `--lora-dir LORA_DIR` | Path to directory with all the loras |
|
||||
| `--no-stream` | Don't stream the text output in real time. |
|
||||
| `--settings SETTINGS_FILE` | Load the default interface settings from this json file. See `settings-template.json` for an example. If you create a file called `settings.json`, this file will be loaded by default without the need to use the `--settings` flag.|
|
||||
| `--extensions EXTENSIONS [EXTENSIONS ...]` | The list of extensions to load. If you want to load more than one extension, write the names separated by spaces. |
|
||||
| `--verbose` | Print the prompts to the terminal. |
|
||||
|
||||
#### Accelerate/transformers
|
||||
|
||||
| Flag | Description |
|
||||
|---------------------------------------------|-------------|
|
||||
| `--cpu` | Use the CPU to generate text. Warning: Training on CPU is extremely slow.|
|
||||
| `--auto-devices` | Automatically split the model across the available GPU(s) and CPU. |
|
||||
| `--gpu-memory GPU_MEMORY [GPU_MEMORY ...]` | Maxmimum GPU memory in GiB to be allocated per GPU. Example: `--gpu-memory 10` for a single GPU, `--gpu-memory 10 5` for two GPUs. You can also set values in MiB like `--gpu-memory 3500MiB`. |
|
||||
| `--cpu-memory CPU_MEMORY` | Maximum CPU memory in GiB to allocate for offloaded weights. Same as above.|
|
||||
| `--disk` | If the model is too large for your GPU(s) and CPU combined, send the remaining layers to the disk. |
|
||||
| `--disk-cache-dir DISK_CACHE_DIR` | Directory to save the disk cache to. Defaults to `cache/`. |
|
||||
| `--load-in-8bit` | Load the model with 8-bit precision.|
|
||||
| `--bf16` | Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU. |
|
||||
| `--no-cache` | Set `use_cache` to False while generating text. This reduces the VRAM usage a bit with a performance cost. |
|
||||
| `--xformers` | Use xformer's memory efficient attention. This should increase your tokens/s. |
|
||||
| `--sdp-attention` | Use torch 2.0's sdp attention. |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--cpu` | Use the CPU to generate text.|
|
||||
| `--auto-devices` | Automatically split the model across the available GPU(s) and CPU.|
|
||||
| `--gpu-memory GPU_MEMORY [GPU_MEMORY ...]` | Maxmimum GPU memory in GiB to be allocated per GPU. Example: `--gpu-memory 10` for a single GPU, `--gpu-memory 10 5` for two GPUs. You can also set values in MiB like `--gpu-memory 3500MiB`. |
|
||||
| `--cpu-memory CPU_MEMORY` | Maximum CPU memory in GiB to allocate for offloaded weights. Same as above.|
|
||||
| `--disk` | If the model is too large for your GPU(s) and CPU combined, send the remaining layers to the disk. |
|
||||
| `--disk-cache-dir DISK_CACHE_DIR` | Directory to save the disk cache to. Defaults to `cache/`. |
|
||||
| `--load-in-8bit` | Load the model with 8-bit precision.|
|
||||
| `--bf16` | Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU. |
|
||||
| `--no-cache` | Set `use_cache` to False while generating text. This reduces the VRAM usage a bit with a performance cost. |
|
||||
|
||||
#### llama.cpp
|
||||
|
||||
| Flag | Description |
|
||||
|-------------|-------------|
|
||||
| `--threads` | Number of threads to use in llama.cpp. |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--threads` | Number of threads to use in llama.cpp. |
|
||||
|
||||
#### GPTQ
|
||||
|
||||
| Flag | Description |
|
||||
|---------------------------|-------------|
|
||||
| `--wbits WBITS` | GPTQ: Load a pre-quantized model with specified precision in bits. 2, 3, 4 and 8 are supported. |
|
||||
| `--model_type MODEL_TYPE` | GPTQ: Model type of pre-quantized model. Currently LLaMA, OPT, and GPT-J are supported. |
|
||||
| `--groupsize GROUPSIZE` | GPTQ: Group size. |
|
||||
| `--pre_layer PRE_LAYER` | GPTQ: The number of layers to allocate to the GPU. Setting this parameter enables CPU offloading for 4-bit models. |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--wbits WBITS` | GPTQ: Load a pre-quantized model with specified precision in bits. 2, 3, 4 and 8 are supported. |
|
||||
| `--model_type MODEL_TYPE` | GPTQ: Model type of pre-quantized model. Currently LLaMA, OPT, and GPT-J are supported. |
|
||||
| `--groupsize GROUPSIZE` | GPTQ: Group size. |
|
||||
| `--pre_layer PRE_LAYER` | GPTQ: The number of layers to allocate to the GPU. Setting this parameter enables CPU offloading for 4-bit models. |
|
||||
|
||||
#### FlexGen
|
||||
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--flexgen` | Enable the use of FlexGen offloading. |
|
||||
| `--percent PERCENT [PERCENT ...]` | FlexGen: allocation percentages. Must be 6 numbers separated by spaces (default: 0, 100, 100, 0, 100, 0). |
|
||||
| `--compress-weight` | FlexGen: Whether to compress weight (default: False).|
|
||||
| `--pin-weight [PIN_WEIGHT]` | FlexGen: whether to pin weights (setting this to False reduces CPU memory by 20%). |
|
||||
| `--flexgen` | Enable the use of FlexGen offloading. |
|
||||
| `--percent PERCENT [PERCENT ...]` | FlexGen: allocation percentages. Must be 6 numbers separated by spaces (default: 0, 100, 100, 0, 100, 0). |
|
||||
| `--compress-weight` | FlexGen: Whether to compress weight (default: False).|
|
||||
| `--pin-weight [PIN_WEIGHT]` | FlexGen: whether to pin weights (setting this to False reduces CPU memory by 20%). |
|
||||
|
||||
#### DeepSpeed
|
||||
|
||||
| Flag | Description |
|
||||
|---------------------------------------|-------------|
|
||||
| `--deepspeed` | Enable the use of DeepSpeed ZeRO-3 for inference via the Transformers integration. |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--deepspeed` | Enable the use of DeepSpeed ZeRO-3 for inference via the Transformers integration. |
|
||||
| `--nvme-offload-dir NVME_OFFLOAD_DIR` | DeepSpeed: Directory to use for ZeRO-3 NVME offloading. |
|
||||
| `--local_rank LOCAL_RANK` | DeepSpeed: Optional argument for distributed setups. |
|
||||
| `--local_rank LOCAL_RANK` | DeepSpeed: Optional argument for distributed setups. |
|
||||
|
||||
#### RWKV
|
||||
|
||||
| Flag | Description |
|
||||
|---------------------------------|-------------|
|
||||
| `--rwkv-strategy RWKV_STRATEGY` | RWKV: The strategy to use while loading the model. Examples: "cpu fp32", "cuda fp16", "cuda fp16i8". |
|
||||
| `--rwkv-cuda-on` | RWKV: Compile the CUDA kernel for better performance. |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--rwkv-strategy RWKV_STRATEGY` | RWKV: The strategy to use while loading the model. Examples: "cpu fp32", "cuda fp16", "cuda fp16i8". |
|
||||
| `--rwkv-cuda-on` | RWKV: Compile the CUDA kernel for better performance. |
|
||||
|
||||
#### Gradio
|
||||
|
||||
| Flag | Description |
|
||||
|---------------------------------------|-------------|
|
||||
| `--listen` | Make the web UI reachable from your local network. |
|
||||
| `--listen-port LISTEN_PORT` | The listening port that the server will use. |
|
||||
| `--share` | Create a public URL. This is useful for running the web UI on Google Colab or similar. |
|
||||
| `--auto-launch` | Open the web UI in the default browser upon launch. |
|
||||
| `--gradio-auth-path GRADIO_AUTH_PATH` | Set the gradio authentication file path. The file should contain one or more user:password pairs in this format: "u1:p1,u2:p2,u3:p3" |
|
||||
| Flag | Description |
|
||||
|------------------|-------------|
|
||||
| `--listen` | Make the web UI reachable from your local network. |
|
||||
| `--listen-port LISTEN_PORT` | The listening port that the server will use. |
|
||||
| `--share` | Create a public URL. This is useful for running the web UI on Google Colab or similar. |
|
||||
| `--auto-launch` | Open the web UI in the default browser upon launch. |
|
||||
| `--gradio-auth-path GRADIO_AUTH_PATH` | Set the gradio authentication file path. The file should contain one or more user:password pairs in this format: "u1:p1,u2:p2,u3:p3" |
|
||||
|
||||
Out of memory errors? [Check the low VRAM guide](https://github.com/oobabooga/text-generation-webui/wiki/Low-VRAM-guide).
|
||||
|
||||
|
||||
@@ -17,7 +17,6 @@ def random_hash():
|
||||
letters = string.ascii_lowercase + string.digits
|
||||
return ''.join(random.choice(letters) for i in range(9))
|
||||
|
||||
|
||||
async def run(context):
|
||||
server = "127.0.0.1"
|
||||
params = {
|
||||
@@ -42,7 +41,7 @@ async def run(context):
|
||||
|
||||
async with websockets.connect(f"ws://{server}:7860/queue/join") as websocket:
|
||||
while content := json.loads(await websocket.recv()):
|
||||
# Python3.10 syntax, replace with if elif on older
|
||||
#Python3.10 syntax, replace with if elif on older
|
||||
match content["msg"]:
|
||||
case "send_hash":
|
||||
await websocket.send(json.dumps({
|
||||
@@ -63,14 +62,13 @@ async def run(context):
|
||||
pass
|
||||
case "process_generating" | "process_completed":
|
||||
yield content["output"]["data"][0]
|
||||
# You can search for your desired end indicator and
|
||||
# You can search for your desired end indicator and
|
||||
# stop generation by closing the websocket here
|
||||
if (content["msg"] == "process_completed"):
|
||||
break
|
||||
|
||||
prompt = "What I would like to say is the following: "
|
||||
|
||||
|
||||
async def get_result():
|
||||
async for response in run(prompt):
|
||||
# Print intermediate steps
|
||||
|
||||
@@ -22,10 +22,10 @@ server = "127.0.0.1"
|
||||
params = {
|
||||
'max_new_tokens': 200,
|
||||
'do_sample': True,
|
||||
'temperature': 0.72,
|
||||
'top_p': 0.73,
|
||||
'temperature': 0.5,
|
||||
'top_p': 0.9,
|
||||
'typical_p': 1,
|
||||
'repetition_penalty': 1.1,
|
||||
'repetition_penalty': 1.05,
|
||||
'encoder_repetition_penalty': 1.0,
|
||||
'top_k': 0,
|
||||
'min_length': 0,
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
name: "### Assistant:"
|
||||
your_name: "### Human:"
|
||||
context: "Below is an instruction that describes a task. Write a response that appropriately completes the request."
|
||||
@@ -13,11 +13,10 @@ import torch
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
|
||||
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog,max_help_position=54))
|
||||
parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
|
||||
args = parser.parse_args()
|
||||
|
||||
|
||||
def disable_torch_init():
|
||||
"""
|
||||
Disable the redundant torch default initialization to accelerate model creation.
|
||||
@@ -32,22 +31,20 @@ def disable_torch_init():
|
||||
torch_layer_norm_init_backup = torch.nn.LayerNorm.reset_parameters
|
||||
setattr(torch.nn.LayerNorm, "reset_parameters", lambda self: None)
|
||||
|
||||
|
||||
def restore_torch_init():
|
||||
"""Rollback the change made by disable_torch_init."""
|
||||
import torch
|
||||
setattr(torch.nn.Linear, "reset_parameters", torch_linear_init_backup)
|
||||
setattr(torch.nn.LayerNorm, "reset_parameters", torch_layer_norm_init_backup)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
path = Path(args.MODEL)
|
||||
model_name = path.name
|
||||
|
||||
print(f"Loading {model_name}...")
|
||||
# disable_torch_init()
|
||||
#disable_torch_init()
|
||||
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
||||
# restore_torch_init()
|
||||
#restore_torch_init()
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(path)
|
||||
|
||||
|
||||
@@ -17,7 +17,7 @@ from pathlib import Path
|
||||
import torch
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
|
||||
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog,max_help_position=54))
|
||||
parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
|
||||
parser.add_argument('--output', type=str, default=None, help='Path to the output folder (default: models/{model_name}_safetensors).')
|
||||
parser.add_argument("--max-shard-size", type=str, default="2GB", help="Maximum size of a shard in GB or MB (default: %(default)s).")
|
||||
|
||||
@@ -36,8 +36,3 @@ div.svelte-362y77>*, div.svelte-362y77>.form>* {
|
||||
.wrap.svelte-6roggh.svelte-6roggh {
|
||||
max-height: 92.5%;
|
||||
}
|
||||
|
||||
/* This is for the microphone button in the whisper extension */
|
||||
.sm.svelte-1ipelgc {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
@@ -64,15 +64,6 @@
|
||||
line-height: 1.428571429 !important;
|
||||
}
|
||||
|
||||
.message-body li {
|
||||
margin-top: 0.5em !important;
|
||||
margin-bottom: 0.5em !important;
|
||||
}
|
||||
|
||||
.message-body li > p {
|
||||
display: inline !important;
|
||||
}
|
||||
|
||||
.dark .message-body p em {
|
||||
color: rgb(138, 138, 138) !important;
|
||||
}
|
||||
|
||||
@@ -18,6 +18,10 @@
|
||||
line-height: 1.428571429;
|
||||
}
|
||||
|
||||
.text p {
|
||||
margin-top: 5px;
|
||||
}
|
||||
|
||||
.username {
|
||||
display: none;
|
||||
}
|
||||
@@ -25,16 +29,9 @@
|
||||
.message-body {}
|
||||
|
||||
.message-body p {
|
||||
margin-bottom: 0 !important;
|
||||
font-size: 15px !important;
|
||||
}
|
||||
|
||||
.message-body li {
|
||||
margin-top: 0.5em !important;
|
||||
margin-bottom: 0.5em !important;
|
||||
}
|
||||
|
||||
.message-body li > p {
|
||||
display: inline !important;
|
||||
line-height: 1.428571429 !important;
|
||||
}
|
||||
|
||||
.dark .message-body p em {
|
||||
@@ -45,20 +42,15 @@
|
||||
color: rgb(110, 110, 110) !important;
|
||||
}
|
||||
|
||||
.gradio-container .chat .assistant-message {
|
||||
padding: 15px;
|
||||
border-radius: 20px;
|
||||
background-color: #0000000f;
|
||||
margin-top: 9px !important;
|
||||
margin-bottom: 18px !important;
|
||||
.assistant-message {
|
||||
padding: 10px;
|
||||
}
|
||||
|
||||
.gradio-container .chat .user-message {
|
||||
padding: 15px;
|
||||
border-radius: 20px;
|
||||
margin-bottom: 9px !important;
|
||||
.user-message {
|
||||
padding: 10px;
|
||||
background-color: #f1f1f1;
|
||||
}
|
||||
|
||||
.dark .chat .assistant-message {
|
||||
background-color: #374151;
|
||||
.dark .user-message {
|
||||
background-color: #ffffff1a;
|
||||
}
|
||||
12
css/main.css
12
css/main.css
@@ -41,7 +41,7 @@ ol li p, ul li p {
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
#main, #parameters, #chat-settings, #interface-mode, #lora, #training-tab, #model-tab {
|
||||
#main, #parameters, #chat-settings, #interface-mode, #lora, #training-tab {
|
||||
border: 0;
|
||||
}
|
||||
|
||||
@@ -67,13 +67,3 @@ span.math.inline {
|
||||
div.svelte-15lo0d8 > *, div.svelte-15lo0d8 > .form > * {
|
||||
flex-wrap: nowrap;
|
||||
}
|
||||
|
||||
.header_bar {
|
||||
background-color: #f7f7f7;
|
||||
margin-bottom: 40px;
|
||||
}
|
||||
|
||||
.dark .header_bar {
|
||||
border: none !important;
|
||||
background-color: #8080802b;
|
||||
}
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
document.getElementById("main").parentNode.childNodes[0].classList.add("header_bar");
|
||||
document.getElementById("main").parentNode.childNodes[0].style = "border: none; background-color: #8080802b; margin-bottom: 40px";
|
||||
document.getElementById("main").parentNode.style = "padding: 0; margin: 0";
|
||||
document.getElementById("main").parentNode.parentNode.parentNode.style = "padding: 0";
|
||||
|
||||
|
||||
@@ -1,31 +0,0 @@
|
||||
version: "3.3"
|
||||
services:
|
||||
text-generation-webui:
|
||||
build:
|
||||
context: .
|
||||
args:
|
||||
# specify which cuda version your card supports: https://developer.nvidia.com/cuda-gpus
|
||||
TORCH_CUDA_ARCH_LIST: ${TORCH_CUDA_ARCH_LIST}
|
||||
WEBUI_VERSION: ${WEBUI_VERSION}
|
||||
env_file: .env
|
||||
ports:
|
||||
- "${HOST_PORT}:${CONTAINER_PORT}"
|
||||
- "${HOST_API_PORT}:${CONTAINER_API_PORT}"
|
||||
stdin_open: true
|
||||
tty: true
|
||||
volumes:
|
||||
- ./characters:/app/characters
|
||||
- ./extensions:/app/extensions
|
||||
- ./loras:/app/loras
|
||||
- ./models:/app/models
|
||||
- ./presets:/app/presets
|
||||
- ./prompts:/app/prompts
|
||||
- ./softprompts:/app/softprompts
|
||||
- ./training:/app/training
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
device_ids: ['0']
|
||||
capabilities: [gpu]
|
||||
@@ -19,6 +19,47 @@ import requests
|
||||
import tqdm
|
||||
from tqdm.contrib.concurrent import thread_map
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('MODEL', type=str, default=None, nargs='?')
|
||||
parser.add_argument('--branch', type=str, default='main', help='Name of the Git branch to download from.')
|
||||
parser.add_argument('--threads', type=int, default=1, help='Number of files to download simultaneously.')
|
||||
parser.add_argument('--text-only', action='store_true', help='Only download text files (txt/json).')
|
||||
parser.add_argument('--output', type=str, default=None, help='The folder where the model should be saved.')
|
||||
parser.add_argument('--clean', action='store_true', help='Does not resume the previous download.')
|
||||
parser.add_argument('--check', action='store_true', help='Validates the checksums of model files.')
|
||||
args = parser.parse_args()
|
||||
|
||||
def get_file(url, output_folder):
|
||||
filename = Path(url.rsplit('/', 1)[1])
|
||||
output_path = output_folder / filename
|
||||
if output_path.exists() and not args.clean:
|
||||
# Check if the file has already been downloaded completely
|
||||
r = requests.get(url, stream=True)
|
||||
total_size = int(r.headers.get('content-length', 0))
|
||||
if output_path.stat().st_size >= total_size:
|
||||
return
|
||||
# Otherwise, resume the download from where it left off
|
||||
headers = {'Range': f'bytes={output_path.stat().st_size}-'}
|
||||
mode = 'ab'
|
||||
else:
|
||||
headers = {}
|
||||
mode = 'wb'
|
||||
|
||||
r = requests.get(url, stream=True, headers=headers)
|
||||
with open(output_path, mode) as f:
|
||||
total_size = int(r.headers.get('content-length', 0))
|
||||
block_size = 1024
|
||||
with tqdm.tqdm(total=total_size, unit='iB', unit_scale=True, bar_format='{l_bar}{bar}| {n_fmt:6}/{total_fmt:6} {rate_fmt:6}') as t:
|
||||
for data in r.iter_content(block_size):
|
||||
t.update(len(data))
|
||||
f.write(data)
|
||||
|
||||
def sanitize_branch_name(branch_name):
|
||||
pattern = re.compile(r"^[a-zA-Z0-9._-]+$")
|
||||
if pattern.match(branch_name):
|
||||
return branch_name
|
||||
else:
|
||||
raise ValueError("Invalid branch name. Only alphanumeric characters, period, underscore and dash are allowed.")
|
||||
|
||||
def select_model_from_default_options():
|
||||
models = {
|
||||
@@ -37,11 +78,11 @@ def select_model_from_default_options():
|
||||
choices = {}
|
||||
|
||||
print("Select the model that you want to download:\n")
|
||||
for i, name in enumerate(models):
|
||||
char = chr(ord('A') + i)
|
||||
for i,name in enumerate(models):
|
||||
char = chr(ord('A')+i)
|
||||
choices[char] = name
|
||||
print(f"{char}) {name}")
|
||||
char = chr(ord('A') + len(models))
|
||||
char = chr(ord('A')+len(models))
|
||||
print(f"{char}) None of the above")
|
||||
|
||||
print()
|
||||
@@ -65,21 +106,7 @@ EleutherAI/pythia-1.4b-deduped
|
||||
|
||||
return model, branch
|
||||
|
||||
|
||||
def sanitize_model_and_branch_names(model, branch):
|
||||
if model[-1] == '/':
|
||||
model = model[:-1]
|
||||
if branch is None:
|
||||
branch = "main"
|
||||
else:
|
||||
pattern = re.compile(r"^[a-zA-Z0-9._-]+$")
|
||||
if not pattern.match(branch):
|
||||
raise ValueError("Invalid branch name. Only alphanumeric characters, period, underscore and dash are allowed.")
|
||||
|
||||
return model, branch
|
||||
|
||||
|
||||
def get_download_links_from_huggingface(model, branch, text_only=False):
|
||||
def get_download_links_from_huggingface(model, branch):
|
||||
base = "https://huggingface.co"
|
||||
page = f"/api/models/{model}/tree/{branch}?cursor="
|
||||
cursor = b""
|
||||
@@ -111,14 +138,14 @@ def get_download_links_from_huggingface(model, branch, text_only=False):
|
||||
is_tokenizer = re.match("tokenizer.*\.model", fname)
|
||||
is_text = re.match(".*\.(txt|json|py|md)", fname) or is_tokenizer
|
||||
|
||||
if any((is_pytorch, is_safetensors, is_pt, is_ggml, is_tokenizer, is_text)):
|
||||
if any((is_pytorch, is_safetensors, is_pt, is_tokenizer, is_text)):
|
||||
if 'lfs' in dict[i]:
|
||||
sha256.append([fname, dict[i]['lfs']['oid']])
|
||||
if is_text:
|
||||
links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
|
||||
classifications.append('text')
|
||||
continue
|
||||
if not text_only:
|
||||
if not args.text_only:
|
||||
links.append(f"https://huggingface.co/{model}/resolve/{branch}/{fname}")
|
||||
if is_safetensors:
|
||||
has_safetensors = True
|
||||
@@ -139,132 +166,85 @@ def get_download_links_from_huggingface(model, branch, text_only=False):
|
||||
|
||||
# If both pytorch and safetensors are available, download safetensors only
|
||||
if (has_pytorch or has_pt) and has_safetensors:
|
||||
for i in range(len(classifications) - 1, -1, -1):
|
||||
for i in range(len(classifications)-1, -1, -1):
|
||||
if classifications[i] in ['pytorch', 'pt']:
|
||||
links.pop(i)
|
||||
|
||||
return links, sha256, is_lora
|
||||
|
||||
def download_files(file_list, output_folder, num_threads=8):
|
||||
thread_map(lambda url: get_file(url, output_folder), file_list, max_workers=num_threads, disable=True)
|
||||
|
||||
def get_output_folder(model, branch, is_lora, base_folder=None):
|
||||
if base_folder is None:
|
||||
if __name__ == '__main__':
|
||||
model = args.MODEL
|
||||
branch = args.branch
|
||||
if model is None:
|
||||
model, branch = select_model_from_default_options()
|
||||
else:
|
||||
if model[-1] == '/':
|
||||
model = model[:-1]
|
||||
branch = args.branch
|
||||
if branch is None:
|
||||
branch = "main"
|
||||
else:
|
||||
try:
|
||||
branch = sanitize_branch_name(branch)
|
||||
except ValueError as err_branch:
|
||||
print(f"Error: {err_branch}")
|
||||
sys.exit()
|
||||
|
||||
links, sha256, is_lora = get_download_links_from_huggingface(model, branch)
|
||||
|
||||
if args.output is not None:
|
||||
base_folder = args.output
|
||||
else:
|
||||
base_folder = 'models' if not is_lora else 'loras'
|
||||
|
||||
output_folder = f"{'_'.join(model.split('/')[-2:])}"
|
||||
if branch != 'main':
|
||||
output_folder += f'_{branch}'
|
||||
output_folder = Path(base_folder) / output_folder
|
||||
return output_folder
|
||||
|
||||
|
||||
def get_single_file(url, output_folder, start_from_scratch=False):
|
||||
filename = Path(url.rsplit('/', 1)[1])
|
||||
output_path = output_folder / filename
|
||||
if output_path.exists() and not start_from_scratch:
|
||||
# Check if the file has already been downloaded completely
|
||||
r = requests.get(url, stream=True)
|
||||
total_size = int(r.headers.get('content-length', 0))
|
||||
if output_path.stat().st_size >= total_size:
|
||||
return
|
||||
# Otherwise, resume the download from where it left off
|
||||
headers = {'Range': f'bytes={output_path.stat().st_size}-'}
|
||||
mode = 'ab'
|
||||
else:
|
||||
headers = {}
|
||||
mode = 'wb'
|
||||
|
||||
r = requests.get(url, stream=True, headers=headers)
|
||||
with open(output_path, mode) as f:
|
||||
total_size = int(r.headers.get('content-length', 0))
|
||||
block_size = 1024
|
||||
with tqdm.tqdm(total=total_size, unit='iB', unit_scale=True, bar_format='{l_bar}{bar}| {n_fmt:6}/{total_fmt:6} {rate_fmt:6}') as t:
|
||||
for data in r.iter_content(block_size):
|
||||
t.update(len(data))
|
||||
f.write(data)
|
||||
|
||||
|
||||
def start_download_threads(file_list, output_folder, start_from_scratch=False, threads=1):
|
||||
thread_map(lambda url: get_single_file(url, output_folder, start_from_scratch=start_from_scratch), file_list, max_workers=threads, disable=True)
|
||||
|
||||
|
||||
def download_model_files(model, branch, links, sha256, output_folder, start_from_scratch=False, threads=1):
|
||||
# Creating the folder and writing the metadata
|
||||
if not output_folder.exists():
|
||||
output_folder.mkdir()
|
||||
with open(output_folder / 'huggingface-metadata.txt', 'w') as f:
|
||||
f.write(f'url: https://huggingface.co/{model}\n')
|
||||
f.write(f'branch: {branch}\n')
|
||||
f.write(f'download date: {str(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))}\n')
|
||||
sha256_str = ''
|
||||
for i in range(len(sha256)):
|
||||
sha256_str += f' {sha256[i][1]} {sha256[i][0]}\n'
|
||||
if sha256_str != '':
|
||||
f.write(f'sha256sum:\n{sha256_str}')
|
||||
|
||||
# Downloading the files
|
||||
print(f"Downloading the model to {output_folder}")
|
||||
start_download_threads(links, output_folder, start_from_scratch=start_from_scratch, threads=threads)
|
||||
|
||||
|
||||
def check_model_files(model, branch, links, sha256, output_folder):
|
||||
# Validate the checksums
|
||||
validated = True
|
||||
for i in range(len(sha256)):
|
||||
fpath = (output_folder / sha256[i][0])
|
||||
|
||||
if not fpath.exists():
|
||||
print(f"The following file is missing: {fpath}")
|
||||
validated = False
|
||||
continue
|
||||
|
||||
with open(output_folder / sha256[i][0], "rb") as f:
|
||||
bytes = f.read()
|
||||
file_hash = hashlib.sha256(bytes).hexdigest()
|
||||
if file_hash != sha256[i][1]:
|
||||
print(f'Checksum failed: {sha256[i][0]} {sha256[i][1]}')
|
||||
validated = False
|
||||
else:
|
||||
print(f'Checksum validated: {sha256[i][0]} {sha256[i][1]}')
|
||||
|
||||
if validated:
|
||||
print('[+] Validated checksums of all model files!')
|
||||
else:
|
||||
print('[-] Invalid checksums. Rerun download-model.py with the --clean flag.')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('MODEL', type=str, default=None, nargs='?')
|
||||
parser.add_argument('--branch', type=str, default='main', help='Name of the Git branch to download from.')
|
||||
parser.add_argument('--threads', type=int, default=1, help='Number of files to download simultaneously.')
|
||||
parser.add_argument('--text-only', action='store_true', help='Only download text files (txt/json).')
|
||||
parser.add_argument('--output', type=str, default=None, help='The folder where the model should be saved.')
|
||||
parser.add_argument('--clean', action='store_true', help='Does not resume the previous download.')
|
||||
parser.add_argument('--check', action='store_true', help='Validates the checksums of model files.')
|
||||
args = parser.parse_args()
|
||||
|
||||
branch = args.branch
|
||||
model = args.MODEL
|
||||
if model is None:
|
||||
model, branch = select_model_from_default_options()
|
||||
|
||||
# Cleaning up the model/branch names
|
||||
try:
|
||||
model, branch = sanitize_model_and_branch_names(model, branch)
|
||||
except ValueError as err_branch:
|
||||
print(f"Error: {err_branch}")
|
||||
sys.exit()
|
||||
|
||||
# Getting the download links from Hugging Face
|
||||
links, sha256, is_lora = get_download_links_from_huggingface(model, branch, text_only=args.text_only)
|
||||
|
||||
# Getting the output folder
|
||||
output_folder = get_output_folder(model, branch, is_lora, base_folder=args.output)
|
||||
|
||||
if args.check:
|
||||
# Check previously downloaded files
|
||||
check_model_files(model, branch, links, sha256, output_folder)
|
||||
# Validate the checksums
|
||||
validated = True
|
||||
for i in range(len(sha256)):
|
||||
fpath = (output_folder / sha256[i][0])
|
||||
|
||||
if not fpath.exists():
|
||||
print(f"The following file is missing: {fpath}")
|
||||
validated = False
|
||||
continue
|
||||
|
||||
with open(output_folder / sha256[i][0], "rb") as f:
|
||||
bytes = f.read()
|
||||
file_hash = hashlib.sha256(bytes).hexdigest()
|
||||
if file_hash != sha256[i][1]:
|
||||
print(f'Checksum failed: {sha256[i][0]} {sha256[i][1]}')
|
||||
validated = False
|
||||
else:
|
||||
print(f'Checksum validated: {sha256[i][0]} {sha256[i][1]}')
|
||||
|
||||
if validated:
|
||||
print('[+] Validated checksums of all model files!')
|
||||
else:
|
||||
print('[-] Invalid checksums. Rerun download-model.py with the --clean flag.')
|
||||
|
||||
else:
|
||||
# Download files
|
||||
download_model_files(model, branch, links, sha256, output_folder, threads=args.threads)
|
||||
|
||||
# Creating the folder and writing the metadata
|
||||
if not output_folder.exists():
|
||||
output_folder.mkdir()
|
||||
with open(output_folder / 'huggingface-metadata.txt', 'w') as f:
|
||||
f.write(f'url: https://huggingface.co/{model}\n')
|
||||
f.write(f'branch: {branch}\n')
|
||||
f.write(f'download date: {str(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))}\n')
|
||||
sha256_str = ''
|
||||
for i in range(len(sha256)):
|
||||
sha256_str += f' {sha256[i][1]} {sha256[i][0]}\n'
|
||||
if sha256_str != '':
|
||||
f.write(f'sha256sum:\n{sha256_str}')
|
||||
|
||||
# Downloading the files
|
||||
print(f"Downloading the model to {output_folder}")
|
||||
download_files(links, output_folder, args.threads)
|
||||
|
||||
@@ -9,7 +9,6 @@ params = {
|
||||
'port': 5000,
|
||||
}
|
||||
|
||||
|
||||
class Handler(BaseHTTPRequestHandler):
|
||||
def do_GET(self):
|
||||
if self.path == '/api/v1/model':
|
||||
@@ -33,7 +32,7 @@ class Handler(BaseHTTPRequestHandler):
|
||||
self.end_headers()
|
||||
|
||||
prompt = body['prompt']
|
||||
prompt_lines = [k.strip() for k in prompt.split('\n')]
|
||||
prompt_lines = [l.strip() for l in prompt.split('\n')]
|
||||
|
||||
max_context = body.get('max_context_length', 2048)
|
||||
|
||||
@@ -41,18 +40,18 @@ class Handler(BaseHTTPRequestHandler):
|
||||
prompt_lines.pop(0)
|
||||
|
||||
prompt = '\n'.join(prompt_lines)
|
||||
generate_params = {
|
||||
'max_new_tokens': int(body.get('max_length', 200)),
|
||||
generate_params = {
|
||||
'max_new_tokens': int(body.get('max_length', 200)),
|
||||
'do_sample': bool(body.get('do_sample', True)),
|
||||
'temperature': float(body.get('temperature', 0.5)),
|
||||
'top_p': float(body.get('top_p', 1)),
|
||||
'typical_p': float(body.get('typical', 1)),
|
||||
'repetition_penalty': float(body.get('rep_pen', 1.1)),
|
||||
'temperature': float(body.get('temperature', 0.5)),
|
||||
'top_p': float(body.get('top_p', 1)),
|
||||
'typical_p': float(body.get('typical', 1)),
|
||||
'repetition_penalty': float(body.get('rep_pen', 1.1)),
|
||||
'encoder_repetition_penalty': 1,
|
||||
'top_k': int(body.get('top_k', 0)),
|
||||
'top_k': int(body.get('top_k', 0)),
|
||||
'min_length': int(body.get('min_length', 0)),
|
||||
'no_repeat_ngram_size': int(body.get('no_repeat_ngram_size', 0)),
|
||||
'num_beams': int(body.get('num_beams', 1)),
|
||||
'no_repeat_ngram_size': int(body.get('no_repeat_ngram_size',0)),
|
||||
'num_beams': int(body.get('num_beams',1)),
|
||||
'penalty_alpha': float(body.get('penalty_alpha', 0)),
|
||||
'length_penalty': float(body.get('length_penalty', 1)),
|
||||
'early_stopping': bool(body.get('early_stopping', False)),
|
||||
@@ -60,7 +59,7 @@ class Handler(BaseHTTPRequestHandler):
|
||||
}
|
||||
|
||||
generator = generate_reply(
|
||||
prompt,
|
||||
prompt,
|
||||
generate_params,
|
||||
stopping_strings=body.get('stopping_strings', []),
|
||||
)
|
||||
@@ -85,9 +84,9 @@ class Handler(BaseHTTPRequestHandler):
|
||||
def run_server():
|
||||
server_addr = ('0.0.0.0' if shared.args.listen else '127.0.0.1', params['port'])
|
||||
server = ThreadingHTTPServer(server_addr, Handler)
|
||||
if shared.args.share:
|
||||
if shared.args.share:
|
||||
try:
|
||||
from flask_cloudflared import _run_cloudflared
|
||||
from flask_cloudflared import _run_cloudflared
|
||||
public_url = _run_cloudflared(params['port'], params['port'] + 1)
|
||||
print(f'Starting KoboldAI compatible api at {public_url}/api')
|
||||
except ImportError:
|
||||
@@ -96,6 +95,5 @@ def run_server():
|
||||
print(f'Starting KoboldAI compatible api at http://{server_addr[0]}:{server_addr[1]}/api')
|
||||
server.serve_forever()
|
||||
|
||||
|
||||
def setup():
|
||||
Thread(target=run_server, daemon=True).start()
|
||||
|
||||
@@ -1,40 +1,24 @@
|
||||
import gradio as gr
|
||||
import os
|
||||
|
||||
# get the current directory of the script
|
||||
current_dir = os.path.dirname(os.path.abspath(__file__))
|
||||
|
||||
# check if the bias_options.txt file exists, if not, create it
|
||||
bias_file = os.path.join(current_dir, "bias_options.txt")
|
||||
if not os.path.isfile(bias_file):
|
||||
with open(bias_file, "w") as f:
|
||||
f.write("*I am so happy*\n*I am so sad*\n*I am so excited*\n*I am so bored*\n*I am so angry*")
|
||||
|
||||
# read bias options from the text file
|
||||
with open(bias_file, "r") as f:
|
||||
bias_options = [line.strip() for line in f.readlines()]
|
||||
|
||||
params = {
|
||||
"activate": True,
|
||||
"bias string": " *I am so happy*",
|
||||
"use custom string": False,
|
||||
}
|
||||
|
||||
|
||||
def input_modifier(string):
|
||||
"""
|
||||
This function is applied to your text inputs before
|
||||
they are fed into the model.
|
||||
"""
|
||||
return string
|
||||
"""
|
||||
|
||||
return string
|
||||
|
||||
def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
"""
|
||||
return string
|
||||
|
||||
return string
|
||||
|
||||
def bot_prefix_modifier(string):
|
||||
"""
|
||||
@@ -42,41 +26,17 @@ def bot_prefix_modifier(string):
|
||||
the prefix text for the Bot and can be used to bias its
|
||||
behavior.
|
||||
"""
|
||||
if params['activate']:
|
||||
if params['use custom string']:
|
||||
return f'{string} {params["custom string"].strip()} '
|
||||
else:
|
||||
return f'{string} {params["bias string"].strip()} '
|
||||
|
||||
if params['activate'] == True:
|
||||
return f'{string} {params["bias string"].strip()} '
|
||||
else:
|
||||
return string
|
||||
|
||||
|
||||
def ui():
|
||||
# Gradio elements
|
||||
activate = gr.Checkbox(value=params['activate'], label='Activate character bias')
|
||||
dropdown_string = gr.Dropdown(choices=bias_options, value=params["bias string"], label='Character bias', info='To edit the options in this dropdown edit the "bias_options.txt" file')
|
||||
use_custom_string = gr.Checkbox(value=False, label='Use custom bias textbox instead of dropdown')
|
||||
custom_string = gr.Textbox(value="", placeholder="Enter custom bias string", label="Custom Character Bias", info='To use this textbox activate the checkbox above')
|
||||
string = gr.Textbox(value=params["bias string"], label='Character bias')
|
||||
|
||||
# Event functions to update the parameters in the backend
|
||||
def update_bias_string(x):
|
||||
if x:
|
||||
params.update({"bias string": x})
|
||||
else:
|
||||
params.update({"bias string": dropdown_string.get()})
|
||||
return x
|
||||
|
||||
def update_custom_string(x):
|
||||
params.update({"custom string": x})
|
||||
|
||||
dropdown_string.change(update_bias_string, dropdown_string, None)
|
||||
custom_string.change(update_custom_string, custom_string, None)
|
||||
string.change(lambda x: params.update({"bias string": x}), string, None)
|
||||
activate.change(lambda x: params.update({"activate": x}), activate, None)
|
||||
use_custom_string.change(lambda x: params.update({"use custom string": x}), use_custom_string, None)
|
||||
|
||||
# Group elements together depending on the selected option
|
||||
def bias_string_group():
|
||||
if use_custom_string.value:
|
||||
return gr.Group([use_custom_string, custom_string])
|
||||
else:
|
||||
return dropdown_string
|
||||
|
||||
@@ -2,11 +2,10 @@ import re
|
||||
from pathlib import Path
|
||||
|
||||
import gradio as gr
|
||||
import modules.shared as shared
|
||||
from elevenlabslib import ElevenLabsUser
|
||||
from elevenlabslib.helpers import save_bytes_to_path
|
||||
|
||||
import modules.shared as shared
|
||||
|
||||
params = {
|
||||
'activate': True,
|
||||
'api_key': '12345',
|
||||
@@ -21,18 +20,16 @@ user_info = None
|
||||
if not shared.args.no_stream:
|
||||
print("Please add --no-stream. This extension is not meant to be used with streaming.")
|
||||
raise ValueError
|
||||
|
||||
|
||||
# Check if the API is valid and refresh the UI accordingly.
|
||||
|
||||
|
||||
def check_valid_api():
|
||||
|
||||
|
||||
global user, user_info, params
|
||||
|
||||
user = ElevenLabsUser(params['api_key'])
|
||||
user_info = user._get_subscription_data()
|
||||
print('checking api')
|
||||
if not params['activate']:
|
||||
if params['activate'] == False:
|
||||
return gr.update(value='Disconnected')
|
||||
elif user_info is None:
|
||||
print('Incorrect API Key')
|
||||
@@ -40,28 +37,24 @@ def check_valid_api():
|
||||
else:
|
||||
print('Got an API Key!')
|
||||
return gr.update(value='Connected')
|
||||
|
||||
|
||||
# Once the API is verified, get the available voices and update the dropdown list
|
||||
|
||||
|
||||
def refresh_voices():
|
||||
|
||||
|
||||
global user, user_info
|
||||
|
||||
|
||||
your_voices = [None]
|
||||
if user_info is not None:
|
||||
for voice in user.get_available_voices():
|
||||
your_voices.append(voice.initialName)
|
||||
return gr.Dropdown.update(choices=your_voices)
|
||||
return gr.Dropdown.update(choices=your_voices)
|
||||
else:
|
||||
return
|
||||
|
||||
|
||||
def remove_surrounded_chars(string):
|
||||
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
||||
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
||||
|
||||
return re.sub('\*[^\*]*?(\*|$)','',string)
|
||||
|
||||
def input_modifier(string):
|
||||
"""
|
||||
@@ -71,17 +64,16 @@ def input_modifier(string):
|
||||
|
||||
return string
|
||||
|
||||
|
||||
def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
"""
|
||||
|
||||
global params, wav_idx, user, user_info
|
||||
|
||||
if not params['activate']:
|
||||
|
||||
if params['activate'] == False:
|
||||
return string
|
||||
elif user_info is None:
|
||||
elif user_info == None:
|
||||
return string
|
||||
|
||||
string = remove_surrounded_chars(string)
|
||||
@@ -92,7 +84,7 @@ def output_modifier(string):
|
||||
|
||||
if string == '':
|
||||
string = 'empty reply, try regenerating'
|
||||
|
||||
|
||||
output_file = Path(f'extensions/elevenlabs_tts/outputs/{wav_idx:06d}.wav'.format(wav_idx))
|
||||
voice = user.get_voices_by_name(params['selected_voice'])[0]
|
||||
audio_data = voice.generate_audio_bytes(string)
|
||||
@@ -102,7 +94,6 @@ def output_modifier(string):
|
||||
wav_idx += 1
|
||||
return string
|
||||
|
||||
|
||||
def ui():
|
||||
|
||||
# Gradio elements
|
||||
@@ -119,4 +110,4 @@ def ui():
|
||||
voice.change(lambda x: params.update({'selected_voice': x}), voice, None)
|
||||
api_key.change(lambda x: params.update({'api_key': x}), api_key, None)
|
||||
connect.click(check_valid_api, [], connection_status)
|
||||
connect.click(refresh_voices, [], voice)
|
||||
connect.click(refresh_voices, [], voice)
|
||||
@@ -85,12 +85,12 @@ def select_character(evt: gr.SelectData):
|
||||
def ui():
|
||||
with gr.Accordion("Character gallery", open=False):
|
||||
update = gr.Button("Refresh")
|
||||
gr.HTML(value="<style>" + generate_css() + "</style>")
|
||||
gr.HTML(value="<style>"+generate_css()+"</style>")
|
||||
gallery = gr.Dataset(components=[gr.HTML(visible=False)],
|
||||
label="",
|
||||
samples=generate_html(),
|
||||
elem_classes=["character-gallery"],
|
||||
samples_per_page=50
|
||||
)
|
||||
label="",
|
||||
samples=generate_html(),
|
||||
elem_classes=["character-gallery"],
|
||||
samples_per_page=50
|
||||
)
|
||||
update.click(generate_html, [], gallery)
|
||||
gallery.select(select_character, None, gradio['character_menu'])
|
||||
gallery.select(select_character, None, gradio['character_menu'])
|
||||
@@ -7,16 +7,14 @@ params = {
|
||||
|
||||
language_codes = {'Afrikaans': 'af', 'Albanian': 'sq', 'Amharic': 'am', 'Arabic': 'ar', 'Armenian': 'hy', 'Azerbaijani': 'az', 'Basque': 'eu', 'Belarusian': 'be', 'Bengali': 'bn', 'Bosnian': 'bs', 'Bulgarian': 'bg', 'Catalan': 'ca', 'Cebuano': 'ceb', 'Chinese (Simplified)': 'zh-CN', 'Chinese (Traditional)': 'zh-TW', 'Corsican': 'co', 'Croatian': 'hr', 'Czech': 'cs', 'Danish': 'da', 'Dutch': 'nl', 'English': 'en', 'Esperanto': 'eo', 'Estonian': 'et', 'Finnish': 'fi', 'French': 'fr', 'Frisian': 'fy', 'Galician': 'gl', 'Georgian': 'ka', 'German': 'de', 'Greek': 'el', 'Gujarati': 'gu', 'Haitian Creole': 'ht', 'Hausa': 'ha', 'Hawaiian': 'haw', 'Hebrew': 'iw', 'Hindi': 'hi', 'Hmong': 'hmn', 'Hungarian': 'hu', 'Icelandic': 'is', 'Igbo': 'ig', 'Indonesian': 'id', 'Irish': 'ga', 'Italian': 'it', 'Japanese': 'ja', 'Javanese': 'jw', 'Kannada': 'kn', 'Kazakh': 'kk', 'Khmer': 'km', 'Korean': 'ko', 'Kurdish': 'ku', 'Kyrgyz': 'ky', 'Lao': 'lo', 'Latin': 'la', 'Latvian': 'lv', 'Lithuanian': 'lt', 'Luxembourgish': 'lb', 'Macedonian': 'mk', 'Malagasy': 'mg', 'Malay': 'ms', 'Malayalam': 'ml', 'Maltese': 'mt', 'Maori': 'mi', 'Marathi': 'mr', 'Mongolian': 'mn', 'Myanmar (Burmese)': 'my', 'Nepali': 'ne', 'Norwegian': 'no', 'Nyanja (Chichewa)': 'ny', 'Pashto': 'ps', 'Persian': 'fa', 'Polish': 'pl', 'Portuguese (Portugal, Brazil)': 'pt', 'Punjabi': 'pa', 'Romanian': 'ro', 'Russian': 'ru', 'Samoan': 'sm', 'Scots Gaelic': 'gd', 'Serbian': 'sr', 'Sesotho': 'st', 'Shona': 'sn', 'Sindhi': 'sd', 'Sinhala (Sinhalese)': 'si', 'Slovak': 'sk', 'Slovenian': 'sl', 'Somali': 'so', 'Spanish': 'es', 'Sundanese': 'su', 'Swahili': 'sw', 'Swedish': 'sv', 'Tagalog (Filipino)': 'tl', 'Tajik': 'tg', 'Tamil': 'ta', 'Telugu': 'te', 'Thai': 'th', 'Turkish': 'tr', 'Ukrainian': 'uk', 'Urdu': 'ur', 'Uzbek': 'uz', 'Vietnamese': 'vi', 'Welsh': 'cy', 'Xhosa': 'xh', 'Yiddish': 'yi', 'Yoruba': 'yo', 'Zulu': 'zu'}
|
||||
|
||||
|
||||
def input_modifier(string):
|
||||
"""
|
||||
This function is applied to your text inputs before
|
||||
they are fed into the model.
|
||||
"""
|
||||
"""
|
||||
|
||||
return GoogleTranslator(source=params['language string'], target='en').translate(string)
|
||||
|
||||
|
||||
def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
@@ -24,7 +22,6 @@ def output_modifier(string):
|
||||
|
||||
return GoogleTranslator(source='en', target=params['language string']).translate(string)
|
||||
|
||||
|
||||
def bot_prefix_modifier(string):
|
||||
"""
|
||||
This function is only applied in chat mode. It modifies
|
||||
@@ -34,7 +31,6 @@ def bot_prefix_modifier(string):
|
||||
|
||||
return string
|
||||
|
||||
|
||||
def ui():
|
||||
# Finding the language name from the language code to use as the default value
|
||||
language_name = list(language_codes.keys())[list(language_codes.values()).index(params['language string'])]
|
||||
|
||||
@@ -1,18 +1,15 @@
|
||||
import gradio as gr
|
||||
import modules.shared as shared
|
||||
import pandas as pd
|
||||
|
||||
import modules.shared as shared
|
||||
|
||||
df = pd.read_csv("https://raw.githubusercontent.com/devbrones/llama-prompts/main/prompts/prompts.csv")
|
||||
|
||||
|
||||
def get_prompt_by_name(name):
|
||||
if name == 'None':
|
||||
return ''
|
||||
else:
|
||||
return df[df['Prompt name'] == name].iloc[0]['Prompt'].replace('\\n', '\n')
|
||||
|
||||
|
||||
def ui():
|
||||
if not shared.is_chat():
|
||||
choices = ['None'] + list(df['Prompt name'])
|
||||
|
||||
@@ -1,78 +0,0 @@
|
||||
## Description:
|
||||
TL;DR: Lets the bot answer you with a picture!
|
||||
|
||||
Stable Diffusion API pictures for TextGen, v.1.1.0
|
||||
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||
|
||||
<details>
|
||||
<summary>Interface overview</summary>
|
||||
|
||||
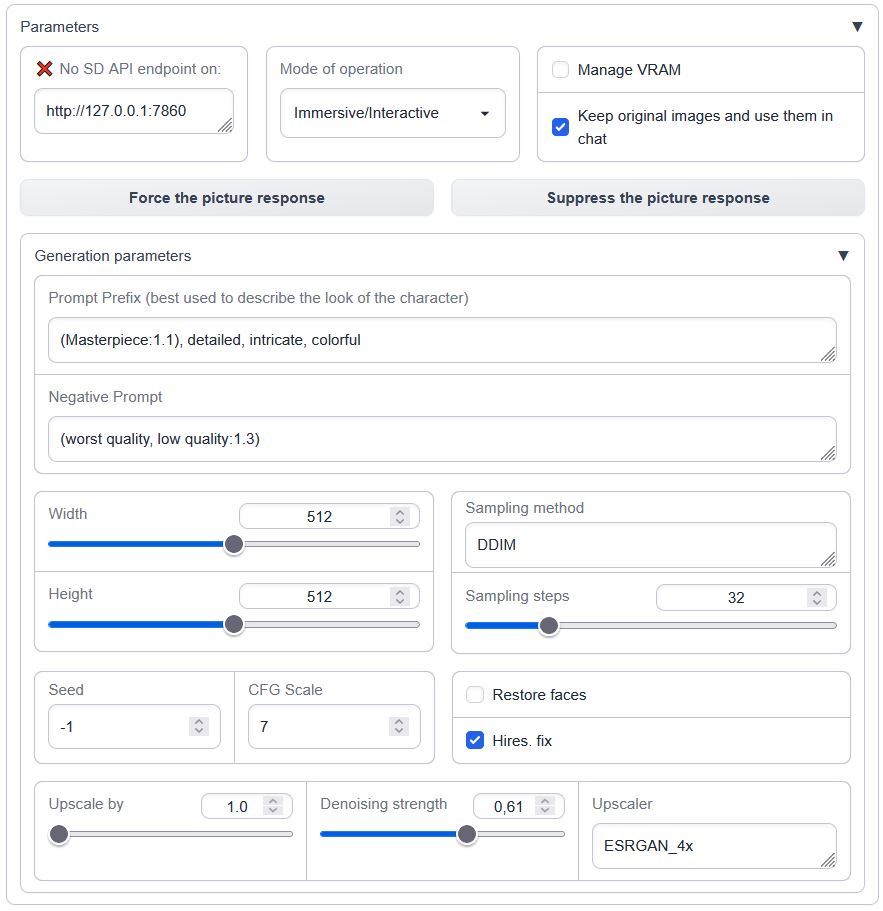
|
||||
|
||||
</details>
|
||||
|
||||
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures` (it's not really required, but completes the picture, *pun intended*).
|
||||
|
||||
The image generation is triggered either:
|
||||
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
||||
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
||||
- always on in Picturebook/Adventure mode (if not currently suppressed by 'Suppress the picture response')
|
||||
|
||||
## Prerequisites
|
||||
|
||||
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
||||
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
||||
|
||||
## Features:
|
||||
- API detection (press enter in the API box)
|
||||
- VRAM management (model shuffling)
|
||||
- Three different operation modes (manual, interactive, always-on)
|
||||
- persistent settings via settings.json
|
||||
|
||||
The model input is modified only in the interactive mode; other two are unaffected. The output pic description is presented differently for Picture-book / Adventure mode.
|
||||
|
||||
Connection check (insert the Auto1111's address and press Enter):
|
||||
|
||||
|
||||
### Persistents settings
|
||||
|
||||
Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
|
||||
present in script.py, ex:
|
||||
|
||||
```json
|
||||
{
|
||||
"sd_api_pictures-manage_VRAM": 1,
|
||||
"sd_api_pictures-save_img": 1,
|
||||
"sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
|
||||
"sd_api_pictures-sampler_name": "DPM++ 2M Karras"
|
||||
}
|
||||
```
|
||||
|
||||
will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
|
||||
|
||||
---
|
||||
|
||||
## Demonstrations:
|
||||
|
||||
Those are examples of the version 1.0.0, but the core functionality is still the same
|
||||
|
||||
<details>
|
||||
<summary>Conversation 1</summary>
|
||||
|
||||
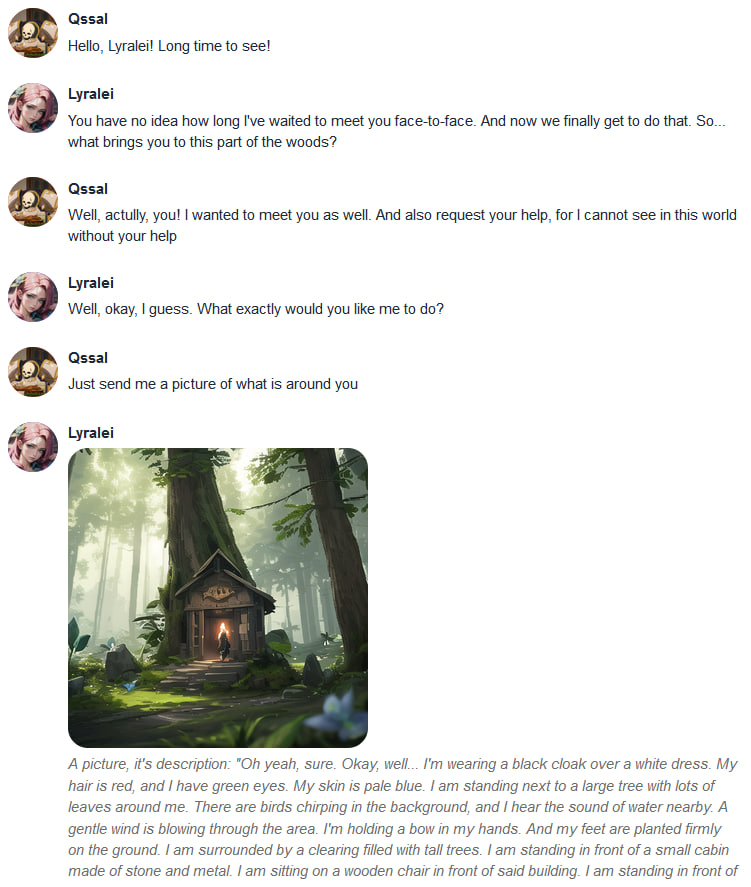
|
||||
|
||||
|
||||
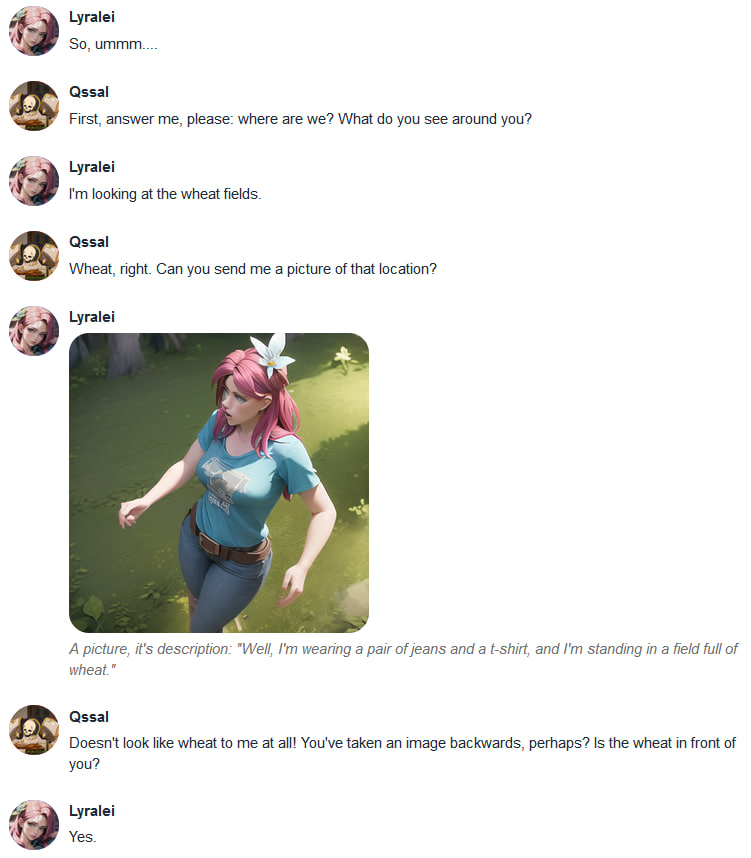
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Conversation 2</summary>
|
||||
|
||||
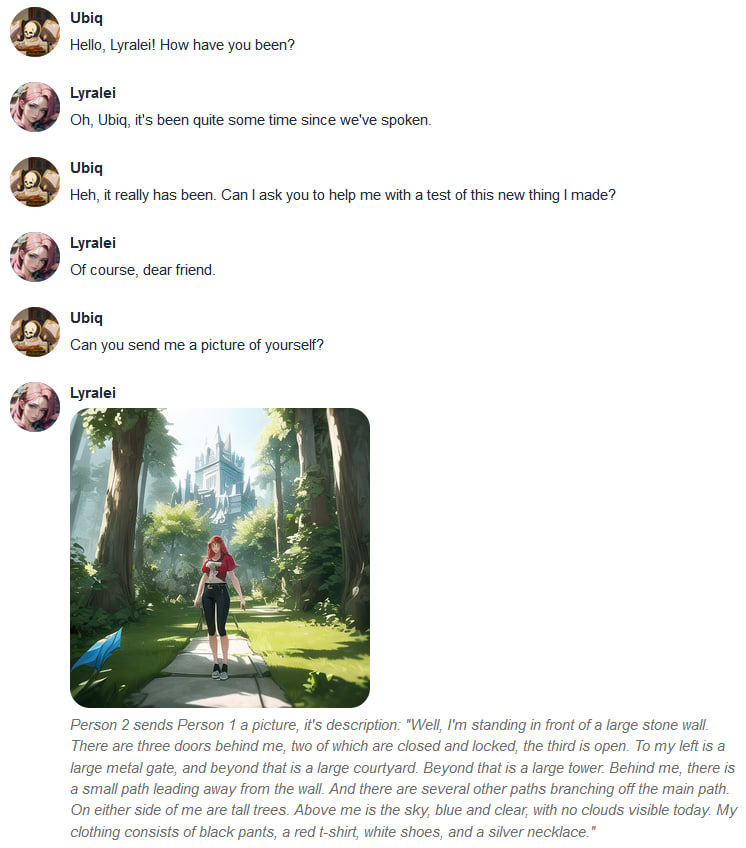
|
||||
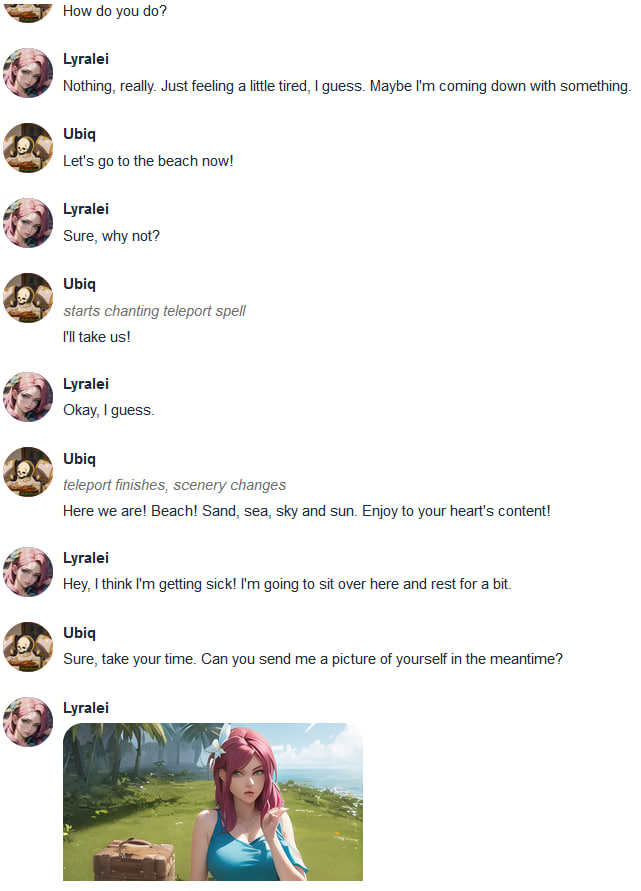
|
||||
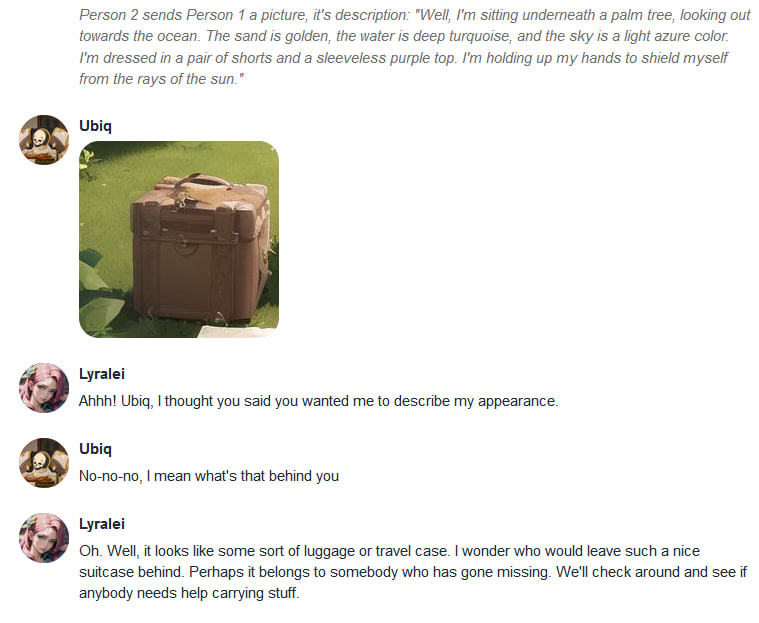
|
||||
|
||||
</details>
|
||||
|
||||
@@ -1,163 +1,102 @@
|
||||
import base64
|
||||
import io
|
||||
import re
|
||||
import time
|
||||
from datetime import date
|
||||
from pathlib import Path
|
||||
|
||||
import gradio as gr
|
||||
import modules.chat as chat
|
||||
import modules.shared as shared
|
||||
import requests
|
||||
import torch
|
||||
from modules.models import reload_model, unload_model
|
||||
from PIL import Image
|
||||
|
||||
torch._C._jit_set_profiling_mode(False)
|
||||
|
||||
# parameters which can be customized in settings.json of webui
|
||||
# parameters which can be customized in settings.json of webui
|
||||
params = {
|
||||
'enable_SD_api': False,
|
||||
'address': 'http://127.0.0.1:7860',
|
||||
'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
|
||||
'manage_VRAM': False,
|
||||
'save_img': False,
|
||||
'SD_model': 'NeverEndingDream', # not used right now
|
||||
'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
|
||||
'SD_model': 'NeverEndingDream', # not really used right now
|
||||
'prompt_prefix': '(Masterpiece:1.1), (solo:1.3), detailed, intricate, colorful',
|
||||
'negative_prompt': '(worst quality, low quality:1.3)',
|
||||
'width': 512,
|
||||
'height': 512,
|
||||
'restore_faces': False,
|
||||
'seed': -1,
|
||||
'sampler_name': 'DDIM',
|
||||
'steps': 32,
|
||||
'cfg_scale': 7
|
||||
'side_length': 512,
|
||||
'restore_faces': False
|
||||
}
|
||||
|
||||
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
||||
|
||||
def give_VRAM_priority(actor):
|
||||
global shared, params
|
||||
|
||||
if actor == 'SD':
|
||||
unload_model()
|
||||
print("Requesting Auto1111 to re-load last checkpoint used...")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
|
||||
elif actor == 'LLM':
|
||||
print("Requesting Auto1111 to vacate VRAM...")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
reload_model()
|
||||
|
||||
elif actor == 'set':
|
||||
print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
|
||||
elif actor == 'reset':
|
||||
print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
|
||||
else:
|
||||
raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
|
||||
|
||||
response.raise_for_status()
|
||||
del response
|
||||
|
||||
|
||||
if params['manage_VRAM']:
|
||||
give_VRAM_priority('set')
|
||||
|
||||
samplers = ['DDIM', 'DPM++ 2M Karras'] # TODO: get the availible samplers with http://{address}}/sdapi/v1/samplers
|
||||
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
||||
|
||||
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
||||
picture_response = False # specifies if the next model response should appear as a picture
|
||||
|
||||
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
||||
picture_response = False # specifies if the next model response should appear as a picture
|
||||
pic_id = 0
|
||||
|
||||
def remove_surrounded_chars(string):
|
||||
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
||||
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
||||
|
||||
|
||||
def triggers_are_in(string):
|
||||
string = remove_surrounded_chars(string)
|
||||
# regex searches for send|main|message|me (at the end of the word) followed by
|
||||
# a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
|
||||
# (?aims) are regex parser flags
|
||||
return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
|
||||
|
||||
return re.sub('\*[^\*]*?(\*|$)','',string)
|
||||
|
||||
# I don't even need input_hijack for this as visible text will be commited to history as the unmodified string
|
||||
def input_modifier(string):
|
||||
"""
|
||||
This function is applied to your text inputs before
|
||||
they are fed into the model.
|
||||
"""
|
||||
|
||||
global params
|
||||
|
||||
if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
|
||||
global params, picture_response
|
||||
if not params['enable_SD_api']:
|
||||
return string
|
||||
|
||||
if triggers_are_in(string): # if we're in it, check for trigger words
|
||||
toggle_generation(True)
|
||||
string = string.lower()
|
||||
if "of" in string:
|
||||
subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
|
||||
string = "Please provide a detailed and vivid description of " + subject
|
||||
else:
|
||||
string = "Please provide a detailed description of your appearance, your surroundings and what you are doing right now"
|
||||
commands = ['send', 'mail', 'me']
|
||||
mediums = ['image', 'pic', 'picture', 'photo']
|
||||
subjects = ['yourself', 'own']
|
||||
lowstr = string.lower()
|
||||
|
||||
# TODO: refactor out to separate handler and also replace detection with a regexp
|
||||
if any(command in lowstr for command in commands) and any(case in lowstr for case in mediums): # trigger the generation if a command signature and a medium signature is found
|
||||
picture_response = True
|
||||
shared.args.no_stream = True # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
||||
shared.processing_message = "*Is sending a picture...*"
|
||||
string = "Please provide a detailed description of your surroundings, how you look and the situation you're in and what you are doing right now"
|
||||
if any(target in lowstr for target in subjects): # the focus of the image should be on the sending character
|
||||
string = "Please provide a detailed and vivid description of how you look and what you are wearing"
|
||||
|
||||
return string
|
||||
|
||||
# Get and save the Stable Diffusion-generated picture
|
||||
def get_SD_pictures(description):
|
||||
|
||||
global params
|
||||
|
||||
if params['manage_VRAM']:
|
||||
give_VRAM_priority('SD')
|
||||
global params, pic_id
|
||||
|
||||
payload = {
|
||||
"prompt": params['prompt_prefix'] + description,
|
||||
"seed": params['seed'],
|
||||
"sampler_name": params['sampler_name'],
|
||||
"steps": params['steps'],
|
||||
"cfg_scale": params['cfg_scale'],
|
||||
"width": params['width'],
|
||||
"height": params['height'],
|
||||
"seed": -1,
|
||||
"sampler_name": "DPM++ 2M Karras",
|
||||
"steps": 32,
|
||||
"cfg_scale": 7,
|
||||
"width": params['side_length'],
|
||||
"height": params['side_length'],
|
||||
"restore_faces": params['restore_faces'],
|
||||
"negative_prompt": params['negative_prompt']
|
||||
}
|
||||
|
||||
print(f'Prompting the image generator via the API on {params["address"]}...')
|
||||
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
|
||||
response.raise_for_status()
|
||||
r = response.json()
|
||||
|
||||
visible_result = ""
|
||||
for img_str in r['images']:
|
||||
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
||||
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",",1)[0])))
|
||||
if params['save_img']:
|
||||
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
|
||||
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
||||
output_file.parent.mkdir(parents=True, exist_ok=True)
|
||||
output_file = Path(f'extensions/sd_api_pictures/outputs/{pic_id:06d}.png')
|
||||
image.save(output_file.as_posix())
|
||||
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
||||
else:
|
||||
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||
image.thumbnail((300, 300))
|
||||
buffered = io.BytesIO()
|
||||
image.save(buffered, format="JPEG")
|
||||
buffered.seek(0)
|
||||
image_bytes = buffered.getvalue()
|
||||
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
||||
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
||||
|
||||
if params['manage_VRAM']:
|
||||
give_VRAM_priority('LLM')
|
||||
|
||||
pic_id += 1
|
||||
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||
image.thumbnail((300, 300))
|
||||
buffered = io.BytesIO()
|
||||
image.save(buffered, format="JPEG")
|
||||
buffered.seek(0)
|
||||
image_bytes = buffered.getvalue()
|
||||
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
||||
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
||||
|
||||
return visible_result
|
||||
|
||||
# TODO: how do I make the UI history ignore the resulting pictures (I don't want HTML to appear in history)
|
||||
@@ -166,8 +105,7 @@ def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
"""
|
||||
|
||||
global picture_response, params
|
||||
global pic_id, picture_response, streaming_state
|
||||
|
||||
if not picture_response:
|
||||
return string
|
||||
@@ -180,19 +118,17 @@ def output_modifier(string):
|
||||
|
||||
if string == '':
|
||||
string = 'no viable description in reply, try regenerating'
|
||||
return string
|
||||
|
||||
text = ""
|
||||
if (params['mode'] < 2):
|
||||
toggle_generation(False)
|
||||
text = f'*Sends a picture which portrays: “{string}”*'
|
||||
else:
|
||||
text = string
|
||||
# I can't for the love of all that's holy get the name from shared.gradio['name1'], so for now it will be like this
|
||||
text = f'*Description: "{string}"*'
|
||||
|
||||
string = get_SD_pictures(string) + "\n" + text
|
||||
image = get_SD_pictures(string)
|
||||
|
||||
return string
|
||||
picture_response = False
|
||||
|
||||
shared.processing_message = "*Is typing...*"
|
||||
shared.args.no_stream = streaming_state
|
||||
return image + "\n" + text
|
||||
|
||||
def bot_prefix_modifier(string):
|
||||
"""
|
||||
@@ -203,92 +139,41 @@ def bot_prefix_modifier(string):
|
||||
|
||||
return string
|
||||
|
||||
|
||||
def toggle_generation(*args):
|
||||
global picture_response, shared, streaming_state
|
||||
|
||||
if not args:
|
||||
picture_response = not picture_response
|
||||
else:
|
||||
picture_response = args[0]
|
||||
|
||||
shared.args.no_stream = True if picture_response else streaming_state # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
||||
shared.processing_message = "*Is sending a picture...*" if picture_response else "*Is typing...*"
|
||||
|
||||
|
||||
def filter_address(address):
|
||||
address = address.strip()
|
||||
# address = re.sub('http(s)?:\/\/|\/$','',address) # remove starting http:// OR https:// OR trailing slash
|
||||
address = re.sub('\/$', '', address) # remove trailing /s
|
||||
if not address.startswith('http'):
|
||||
address = 'http://' + address
|
||||
return address
|
||||
|
||||
|
||||
def SD_api_address_update(address):
|
||||
|
||||
global params
|
||||
|
||||
msg = "✔️ SD API is found on:"
|
||||
address = filter_address(address)
|
||||
params.update({"address": address})
|
||||
try:
|
||||
response = requests.get(url=f'{params["address"]}/sdapi/v1/sd-models')
|
||||
response.raise_for_status()
|
||||
# r = response.json()
|
||||
except:
|
||||
msg = "❌ No SD API endpoint on:"
|
||||
|
||||
return gr.Textbox.update(label=msg)
|
||||
|
||||
def force_pic():
|
||||
global picture_response
|
||||
picture_response = True
|
||||
|
||||
def ui():
|
||||
|
||||
# Gradio elements
|
||||
# gr.Markdown('### Stable Diffusion API Pictures') # Currently the name of extension is shown as the title
|
||||
with gr.Accordion("Parameters", open=True):
|
||||
with gr.Accordion("Stable Diffusion api integration", open=True):
|
||||
with gr.Row():
|
||||
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Auto1111\'s WebUI address')
|
||||
mode = gr.Dropdown(["Manual", "Immersive/Interactive", "Picturebook/Adventure"], value="Manual", label="Mode of operation", type="index")
|
||||
with gr.Column(scale=1, min_width=300):
|
||||
manage_VRAM = gr.Checkbox(value=params['manage_VRAM'], label='Manage VRAM')
|
||||
save_img = gr.Checkbox(value=params['save_img'], label='Keep original images and use them in chat')
|
||||
|
||||
force_pic = gr.Button("Force the picture response")
|
||||
suppr_pic = gr.Button("Suppress the picture response")
|
||||
with gr.Column():
|
||||
enable = gr.Checkbox(value=params['enable_SD_api'], label='Activate SD Api integration')
|
||||
save_img = gr.Checkbox(value=params['save_img'], label='Keep original received images in the outputs subdir')
|
||||
with gr.Column():
|
||||
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Stable Diffusion host address')
|
||||
|
||||
with gr.Row():
|
||||
force_btn = gr.Button("Force the next response to be a picture")
|
||||
generate_now_btn = gr.Button("Generate an image response to the input")
|
||||
|
||||
with gr.Accordion("Generation parameters", open=False):
|
||||
prompt_prefix = gr.Textbox(placeholder=params['prompt_prefix'], value=params['prompt_prefix'], label='Prompt Prefix (best used to describe the look of the character)')
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
||||
sampler_name = gr.Textbox(placeholder=params['sampler_name'], value=params['sampler_name'], label='Sampler')
|
||||
with gr.Column():
|
||||
width = gr.Slider(256, 768, value=params['width'], step=64, label='Width')
|
||||
height = gr.Slider(256, 768, value=params['height'], step=64, label='Height')
|
||||
with gr.Row():
|
||||
steps = gr.Number(label="Steps:", value=params['steps'])
|
||||
seed = gr.Number(label="Seed:", value=params['seed'])
|
||||
cfg_scale = gr.Number(label="CFG Scale:", value=params['cfg_scale'])
|
||||
|
||||
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
||||
dimensions = gr.Slider(256,702,value=params['side_length'],step=64,label='Image dimensions')
|
||||
# model = gr.Dropdown(value=SD_models[0], choices=SD_models, label='Model')
|
||||
|
||||
# Event functions to update the parameters in the backend
|
||||
address.change(lambda x: params.update({"address": filter_address(x)}), address, None)
|
||||
mode.select(lambda x: params.update({"mode": x}), mode, None)
|
||||
mode.select(lambda x: toggle_generation(x > 1), inputs=mode, outputs=None)
|
||||
manage_VRAM.change(lambda x: params.update({"manage_VRAM": x}), manage_VRAM, None)
|
||||
manage_VRAM.change(lambda x: give_VRAM_priority('set' if x else 'reset'), inputs=manage_VRAM, outputs=None)
|
||||
enable.change(lambda x: params.update({"enable_SD_api": x}), enable, None)
|
||||
save_img.change(lambda x: params.update({"save_img": x}), save_img, None)
|
||||
|
||||
address.submit(fn=SD_api_address_update, inputs=address, outputs=address)
|
||||
address.change(lambda x: params.update({"address": x}), address, None)
|
||||
prompt_prefix.change(lambda x: params.update({"prompt_prefix": x}), prompt_prefix, None)
|
||||
negative_prompt.change(lambda x: params.update({"negative_prompt": x}), negative_prompt, None)
|
||||
width.change(lambda x: params.update({"width": x}), width, None)
|
||||
height.change(lambda x: params.update({"height": x}), height, None)
|
||||
dimensions.change(lambda x: params.update({"side_length": x}), dimensions, None)
|
||||
# model.change(lambda x: params.update({"SD_model": x}), model, None)
|
||||
|
||||
sampler_name.change(lambda x: params.update({"sampler_name": x}), sampler_name, None)
|
||||
steps.change(lambda x: params.update({"steps": x}), steps, None)
|
||||
seed.change(lambda x: params.update({"seed": x}), seed, None)
|
||||
cfg_scale.change(lambda x: params.update({"cfg_scale": x}), cfg_scale, None)
|
||||
|
||||
force_pic.click(lambda x: toggle_generation(True), inputs=force_pic, outputs=None)
|
||||
suppr_pic.click(lambda x: toggle_generation(False), inputs=suppr_pic, outputs=None)
|
||||
force_btn.click(force_pic)
|
||||
generate_now_btn.click(force_pic)
|
||||
generate_now_btn.click(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream)
|
||||
@@ -17,15 +17,13 @@ input_hijack = {
|
||||
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
|
||||
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", torch_dtype=torch.float32).to("cpu")
|
||||
|
||||
|
||||
def caption_image(raw_image):
|
||||
inputs = processor(raw_image.convert('RGB'), return_tensors="pt").to("cpu", torch.float32)
|
||||
out = model.generate(**inputs, max_new_tokens=100)
|
||||
return processor.decode(out[0], skip_special_tokens=True)
|
||||
|
||||
|
||||
def generate_chat_picture(picture, name1, name2):
|
||||
text = f'*{name1} sends {name2} a picture that contains the following: “{caption_image(picture)}”*'
|
||||
text = f'*{name1} sends {name2} a picture that contains the following: "{caption_image(picture)}"*'
|
||||
# lower the resolution of sent images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||
picture.thumbnail((300, 300))
|
||||
buffer = BytesIO()
|
||||
@@ -34,7 +32,6 @@ def generate_chat_picture(picture, name1, name2):
|
||||
visible_text = f'<img src="data:image/jpeg;base64,{img_str}" alt="{text}">'
|
||||
return text, visible_text
|
||||
|
||||
|
||||
def ui():
|
||||
picture_select = gr.Image(label='Send a picture', type='pil')
|
||||
|
||||
@@ -45,4 +42,4 @@ def ui():
|
||||
picture_select.upload(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream)
|
||||
|
||||
# Clear the picture from the upload field
|
||||
picture_select.upload(lambda: None, [], [picture_select], show_progress=False)
|
||||
picture_select.upload(lambda : None, [], [picture_select], show_progress=False)
|
||||
|
||||
@@ -1,5 +1,6 @@
|
||||
ipython
|
||||
num2words
|
||||
omegaconf
|
||||
pydub
|
||||
PyYAML
|
||||
torch
|
||||
torchaudio
|
||||
|
||||
@@ -1,16 +1,14 @@
|
||||
import re
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import gradio as gr
|
||||
import modules.chat as chat
|
||||
import modules.shared as shared
|
||||
import torch
|
||||
|
||||
from extensions.silero_tts import tts_preprocessor
|
||||
from modules import chat, shared
|
||||
from modules.html_generator import chat_html_wrapper
|
||||
|
||||
torch._C._jit_set_profiling_mode(False)
|
||||
|
||||
|
||||
params = {
|
||||
'activate': True,
|
||||
'speaker': 'en_56',
|
||||
@@ -22,14 +20,13 @@ params = {
|
||||
'autoplay': True,
|
||||
'voice_pitch': 'medium',
|
||||
'voice_speed': 'medium',
|
||||
'local_cache_path': '' # User can override the default cache path to something other via settings.json
|
||||
}
|
||||
|
||||
current_params = params.copy()
|
||||
voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
|
||||
voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
|
||||
voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
|
||||
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
||||
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
||||
|
||||
# Used for making text xml compatible, needed for voice pitch and speed control
|
||||
table = str.maketrans({
|
||||
@@ -40,31 +37,26 @@ table = str.maketrans({
|
||||
'"': """,
|
||||
})
|
||||
|
||||
|
||||
def xmlesc(txt):
|
||||
return txt.translate(table)
|
||||
|
||||
|
||||
def load_model():
|
||||
torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
|
||||
model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
|
||||
if Path(model_path).is_file():
|
||||
print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
|
||||
model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
|
||||
else:
|
||||
print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
|
||||
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
||||
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
||||
model.to(params['device'])
|
||||
return model
|
||||
model = load_model()
|
||||
|
||||
def remove_surrounded_chars(string):
|
||||
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
||||
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||
return re.sub('\*[^\*]*?(\*|$)','',string)
|
||||
|
||||
def remove_tts_from_history(name1, name2, mode):
|
||||
def remove_tts_from_history(name1, name2):
|
||||
for i, entry in enumerate(shared.history['internal']):
|
||||
shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]
|
||||
return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
return chat.generate_chat_output(shared.history['visible'], name1, name2, shared.character)
|
||||
|
||||
|
||||
def toggle_text_in_history(name1, name2, mode):
|
||||
def toggle_text_in_history(name1, name2):
|
||||
for i, entry in enumerate(shared.history['visible']):
|
||||
visible_reply = entry[1]
|
||||
if visible_reply.startswith('<audio'):
|
||||
@@ -73,8 +65,7 @@ def toggle_text_in_history(name1, name2, mode):
|
||||
shared.history['visible'][i] = [shared.history['visible'][i][0], f"{visible_reply.split('</audio>')[0]}</audio>\n\n{reply}"]
|
||||
else:
|
||||
shared.history['visible'][i] = [shared.history['visible'][i][0], f"{visible_reply.split('</audio>')[0]}</audio>"]
|
||||
return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
|
||||
return chat.generate_chat_output(shared.history['visible'], name1, name2, shared.character)
|
||||
|
||||
def input_modifier(string):
|
||||
"""
|
||||
@@ -84,13 +75,12 @@ def input_modifier(string):
|
||||
|
||||
# Remove autoplay from the last reply
|
||||
if shared.is_chat() and len(shared.history['internal']) > 0:
|
||||
shared.history['visible'][-1] = [shared.history['visible'][-1][0], shared.history['visible'][-1][1].replace('controls autoplay>', 'controls>')]
|
||||
shared.history['visible'][-1] = [shared.history['visible'][-1][0], shared.history['visible'][-1][1].replace('controls autoplay>','controls>')]
|
||||
|
||||
shared.processing_message = "*Is recording a voice message...*"
|
||||
shared.args.no_stream = True # Disable streaming cause otherwise the audio output will stutter and begin anew every time the message is being updated
|
||||
shared.args.no_stream = True # Disable streaming cause otherwise the audio output will stutter and begin anew every time the message is being updated
|
||||
return string
|
||||
|
||||
|
||||
def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
@@ -104,11 +94,15 @@ def output_modifier(string):
|
||||
current_params = params.copy()
|
||||
break
|
||||
|
||||
if not params['activate']:
|
||||
if params['activate'] == False:
|
||||
return string
|
||||
|
||||
original_string = string
|
||||
string = tts_preprocessor.preprocess(string)
|
||||
string = remove_surrounded_chars(string)
|
||||
string = string.replace('"', '')
|
||||
string = string.replace('“', '')
|
||||
string = string.replace('\n', ' ')
|
||||
string = string.strip()
|
||||
|
||||
if string == '':
|
||||
string = '*Empty reply, try regenerating*'
|
||||
@@ -124,10 +118,9 @@ def output_modifier(string):
|
||||
string += f'\n\n{original_string}'
|
||||
|
||||
shared.processing_message = "*Is typing...*"
|
||||
shared.args.no_stream = streaming_state # restore the streaming option to the previous value
|
||||
shared.args.no_stream = streaming_state # restore the streaming option to the previous value
|
||||
return string
|
||||
|
||||
|
||||
def bot_prefix_modifier(string):
|
||||
"""
|
||||
This function is only applied in chat mode. It modifies
|
||||
@@ -137,25 +130,17 @@ def bot_prefix_modifier(string):
|
||||
|
||||
return string
|
||||
|
||||
|
||||
def setup():
|
||||
global model
|
||||
model = load_model()
|
||||
|
||||
|
||||
def ui():
|
||||
# Gradio elements
|
||||
with gr.Accordion("Silero TTS"):
|
||||
with gr.Row():
|
||||
activate = gr.Checkbox(value=params['activate'], label='Activate TTS')
|
||||
autoplay = gr.Checkbox(value=params['autoplay'], label='Play TTS automatically')
|
||||
|
||||
show_text = gr.Checkbox(value=params['show_text'], label='Show message text under audio player')
|
||||
voice = gr.Dropdown(value=params['speaker'], choices=voices_by_gender, label='TTS voice')
|
||||
with gr.Row():
|
||||
v_pitch = gr.Dropdown(value=params['voice_pitch'], choices=voice_pitches, label='Voice pitch')
|
||||
v_speed = gr.Dropdown(value=params['voice_speed'], choices=voice_speeds, label='Voice speed')
|
||||
|
||||
with gr.Row():
|
||||
convert = gr.Button('Permanently replace audios with the message texts')
|
||||
convert_cancel = gr.Button('Cancel', visible=False)
|
||||
@@ -163,20 +148,20 @@ def ui():
|
||||
|
||||
# Convert history with confirmation
|
||||
convert_arr = [convert_confirm, convert, convert_cancel]
|
||||
convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
|
||||
convert_confirm.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
|
||||
convert_confirm.click(remove_tts_from_history, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], shared.gradio['display'])
|
||||
convert_confirm.click(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
convert_cancel.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
|
||||
convert.click(lambda :[gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
|
||||
convert_confirm.click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
|
||||
convert_confirm.click(remove_tts_from_history, [shared.gradio['name1'], shared.gradio['name2']], shared.gradio['display'])
|
||||
convert_confirm.click(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
convert_cancel.click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
|
||||
|
||||
# Toggle message text in history
|
||||
show_text.change(lambda x: params.update({"show_text": x}), show_text, None)
|
||||
show_text.change(toggle_text_in_history, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], shared.gradio['display'])
|
||||
show_text.change(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
show_text.change(toggle_text_in_history, [shared.gradio['name1'], shared.gradio['name2']], shared.gradio['display'])
|
||||
show_text.change(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
|
||||
# Event functions to update the parameters in the backend
|
||||
activate.change(lambda x: params.update({"activate": x}), activate, None)
|
||||
autoplay.change(lambda x: params.update({"autoplay": x}), autoplay, None)
|
||||
voice.change(lambda x: params.update({"speaker": x}), voice, None)
|
||||
v_pitch.change(lambda x: params.update({"voice_pitch": x}), v_pitch, None)
|
||||
v_speed.change(lambda x: params.update({"voice_speed": x}), v_speed, None)
|
||||
v_speed.change(lambda x: params.update({"voice_speed": x}), v_speed, None)
|
||||
@@ -1,81 +0,0 @@
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import tts_preprocessor
|
||||
|
||||
torch._C._jit_set_profiling_mode(False)
|
||||
|
||||
|
||||
params = {
|
||||
'activate': True,
|
||||
'speaker': 'en_49',
|
||||
'language': 'en',
|
||||
'model_id': 'v3_en',
|
||||
'sample_rate': 48000,
|
||||
'device': 'cpu',
|
||||
'show_text': True,
|
||||
'autoplay': True,
|
||||
'voice_pitch': 'medium',
|
||||
'voice_speed': 'medium',
|
||||
}
|
||||
|
||||
current_params = params.copy()
|
||||
voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
|
||||
voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
|
||||
voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
|
||||
|
||||
# Used for making text xml compatible, needed for voice pitch and speed control
|
||||
table = str.maketrans({
|
||||
"<": "<",
|
||||
">": ">",
|
||||
"&": "&",
|
||||
"'": "'",
|
||||
'"': """,
|
||||
})
|
||||
|
||||
|
||||
def xmlesc(txt):
|
||||
return txt.translate(table)
|
||||
|
||||
|
||||
def load_model():
|
||||
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
|
||||
model.to(params['device'])
|
||||
return model
|
||||
|
||||
|
||||
model = load_model()
|
||||
|
||||
|
||||
def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
"""
|
||||
|
||||
global model, current_params
|
||||
|
||||
original_string = string
|
||||
string = tts_preprocessor.preprocess(string)
|
||||
processed_string = string
|
||||
|
||||
if string == '':
|
||||
string = '*Empty reply, try regenerating*'
|
||||
else:
|
||||
output_file = Path(f'extensions/silero_tts/outputs/test_{int(time.time())}.wav')
|
||||
prosody = '<prosody rate="{}" pitch="{}">'.format(params['voice_speed'], params['voice_pitch'])
|
||||
silero_input = f'<speak>{prosody}{xmlesc(string)}</prosody></speak>'
|
||||
model.save_wav(ssml_text=silero_input, speaker=params['speaker'], sample_rate=int(params['sample_rate']), audio_path=str(output_file))
|
||||
|
||||
autoplay = 'autoplay' if params['autoplay'] else ''
|
||||
string = f'<audio src="file/{output_file.as_posix()}" controls {autoplay}></audio>'
|
||||
|
||||
if params['show_text']:
|
||||
string += f'\n\n{original_string}\n\nProcessed:\n{processed_string}'
|
||||
|
||||
print(string)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
import sys
|
||||
output_modifier(sys.argv[1])
|
||||
@@ -1,194 +0,0 @@
|
||||
import re
|
||||
|
||||
from num2words import num2words
|
||||
|
||||
punctuation = r'[\s,.?!/)\'\]>]'
|
||||
alphabet_map = {
|
||||
"A": " Ei ",
|
||||
"B": " Bee ",
|
||||
"C": " See ",
|
||||
"D": " Dee ",
|
||||
"E": " Eee ",
|
||||
"F": " Eff ",
|
||||
"G": " Jee ",
|
||||
"H": " Eich ",
|
||||
"I": " Eye ",
|
||||
"J": " Jay ",
|
||||
"K": " Kay ",
|
||||
"L": " El ",
|
||||
"M": " Emm ",
|
||||
"N": " Enn ",
|
||||
"O": " Ohh ",
|
||||
"P": " Pee ",
|
||||
"Q": " Queue ",
|
||||
"R": " Are ",
|
||||
"S": " Ess ",
|
||||
"T": " Tee ",
|
||||
"U": " You ",
|
||||
"V": " Vee ",
|
||||
"W": " Double You ",
|
||||
"X": " Ex ",
|
||||
"Y": " Why ",
|
||||
"Z": " Zed " # Zed is weird, as I (da3dsoul) am American, but most of the voice models sound British, so it matches
|
||||
}
|
||||
|
||||
|
||||
def preprocess(string):
|
||||
# the order for some of these matter
|
||||
# For example, you need to remove the commas in numbers before expanding them
|
||||
string = remove_surrounded_chars(string)
|
||||
string = string.replace('"', '')
|
||||
string = string.replace('\u201D', '').replace('\u201C', '') # right and left quote
|
||||
string = string.replace('\u201F', '') # italic looking quote
|
||||
string = string.replace('\n', ' ')
|
||||
string = convert_num_locale(string)
|
||||
string = replace_negative(string)
|
||||
string = replace_roman(string)
|
||||
string = hyphen_range_to(string)
|
||||
string = num_to_words(string)
|
||||
|
||||
# TODO Try to use a ML predictor to expand abbreviations. It's hard, dependent on context, and whether to actually
|
||||
# try to say the abbreviation or spell it out as I've done below is not agreed upon
|
||||
|
||||
# For now, expand abbreviations to pronunciations
|
||||
# replace_abbreviations adds a lot of unnecessary whitespace to ensure separation
|
||||
string = replace_abbreviations(string)
|
||||
string = replace_lowercase_abbreviations(string)
|
||||
|
||||
# cleanup whitespaces
|
||||
# remove whitespace before punctuation
|
||||
string = re.sub(rf'\s+({punctuation})', r'\1', string)
|
||||
string = string.strip()
|
||||
# compact whitespace
|
||||
string = ' '.join(string.split())
|
||||
|
||||
return string
|
||||
|
||||
|
||||
def remove_surrounded_chars(string):
|
||||
# this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
|
||||
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||
return re.sub(r'\*[^*]*?(\*|$)', '', string)
|
||||
|
||||
|
||||
def convert_num_locale(text):
|
||||
# This detects locale and converts it to American without comma separators
|
||||
pattern = re.compile(r'(?:\s|^)\d{1,3}(?:\.\d{3})+(,\d+)(?:\s|$)')
|
||||
result = text
|
||||
while True:
|
||||
match = pattern.search(result)
|
||||
if match is None:
|
||||
break
|
||||
|
||||
start = match.start()
|
||||
end = match.end()
|
||||
result = result[0:start] + result[start:end].replace('.', '').replace(',', '.') + result[end:len(result)]
|
||||
|
||||
# removes comma separators from existing American numbers
|
||||
pattern = re.compile(r'(\d),(\d)')
|
||||
result = pattern.sub(r'\1\2', result)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def replace_negative(string):
|
||||
# handles situations like -5. -5 would become negative 5, which would then be expanded to negative five
|
||||
return re.sub(rf'(\s)(-)(\d+)({punctuation})', r'\1negative \3\4', string)
|
||||
|
||||
|
||||
def replace_roman(string):
|
||||
# find a string of roman numerals.
|
||||
# Only 2 or more, to avoid capturing I and single character abbreviations, like names
|
||||
pattern = re.compile(rf'\s[IVXLCDM]{{2,}}{punctuation}')
|
||||
result = string
|
||||
while True:
|
||||
match = pattern.search(result)
|
||||
if match is None:
|
||||
break
|
||||
|
||||
start = match.start()
|
||||
end = match.end()
|
||||
result = result[0:start + 1] + str(roman_to_int(result[start + 1:end - 1])) + result[end - 1:len(result)]
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def roman_to_int(s):
|
||||
rom_val = {'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000}
|
||||
int_val = 0
|
||||
for i in range(len(s)):
|
||||
if i > 0 and rom_val[s[i]] > rom_val[s[i - 1]]:
|
||||
int_val += rom_val[s[i]] - 2 * rom_val[s[i - 1]]
|
||||
else:
|
||||
int_val += rom_val[s[i]]
|
||||
return int_val
|
||||
|
||||
|
||||
def hyphen_range_to(text):
|
||||
pattern = re.compile(r'(\d+)[-–](\d+)')
|
||||
result = pattern.sub(lambda x: x.group(1) + ' to ' + x.group(2), text)
|
||||
return result
|
||||
|
||||
|
||||
def num_to_words(text):
|
||||
# 1000 or 10.23
|
||||
pattern = re.compile(r'\d+\.\d+|\d+')
|
||||
result = pattern.sub(lambda x: num2words(float(x.group())), text)
|
||||
return result
|
||||
|
||||
|
||||
def replace_abbreviations(string):
|
||||
# abbreviations 1 to 4 characters long. It will get things like A and I, but those are pronounced with their letter
|
||||
pattern = re.compile(rf'(^|[\s(.\'\[<])([A-Z]{{1,4}})({punctuation}|$)')
|
||||
result = string
|
||||
while True:
|
||||
match = pattern.search(result)
|
||||
if match is None:
|
||||
break
|
||||
|
||||
start = match.start()
|
||||
end = match.end()
|
||||
result = result[0:start] + replace_abbreviation(result[start:end]) + result[end:len(result)]
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def replace_lowercase_abbreviations(string):
|
||||
# abbreviations 1 to 4 characters long, separated by dots i.e. e.g.
|
||||
pattern = re.compile(rf'(^|[\s(.\'\[<])(([a-z]\.){{1,4}})({punctuation}|$)')
|
||||
result = string
|
||||
while True:
|
||||
match = pattern.search(result)
|
||||
if match is None:
|
||||
break
|
||||
|
||||
start = match.start()
|
||||
end = match.end()
|
||||
result = result[0:start] + replace_abbreviation(result[start:end].upper()) + result[end:len(result)]
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def replace_abbreviation(string):
|
||||
result = ""
|
||||
for char in string:
|
||||
result += match_mapping(char)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def match_mapping(char):
|
||||
for mapping in alphabet_map.keys():
|
||||
if char == mapping:
|
||||
return alphabet_map[char]
|
||||
|
||||
return char
|
||||
|
||||
|
||||
def __main__(args):
|
||||
print(preprocess(args[1]))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
import sys
|
||||
__main__(sys.argv)
|
||||
@@ -1,6 +1,5 @@
|
||||
import gradio as gr
|
||||
import speech_recognition as sr
|
||||
from modules import shared
|
||||
|
||||
input_hijack = {
|
||||
'state': False,
|
||||
@@ -8,7 +7,7 @@ input_hijack = {
|
||||
}
|
||||
|
||||
|
||||
def do_stt(audio):
|
||||
def do_stt(audio, text_state=""):
|
||||
transcription = ""
|
||||
r = sr.Recognizer()
|
||||
|
||||
@@ -22,23 +21,34 @@ def do_stt(audio):
|
||||
except sr.RequestError as e:
|
||||
print("Could not request results from Whisper", e)
|
||||
|
||||
return transcription
|
||||
input_hijack.update({"state": True, "value": [transcription, transcription]})
|
||||
|
||||
text_state += transcription + " "
|
||||
return text_state, text_state
|
||||
|
||||
|
||||
def auto_transcribe(audio, auto_submit):
|
||||
def update_hijack(val):
|
||||
input_hijack.update({"state": True, "value": [val, val]})
|
||||
return val
|
||||
|
||||
|
||||
def auto_transcribe(audio, audio_auto, text_state=""):
|
||||
if audio is None:
|
||||
return "", ""
|
||||
|
||||
transcription = do_stt(audio)
|
||||
if auto_submit:
|
||||
input_hijack.update({"state": True, "value": [transcription, transcription]})
|
||||
|
||||
return transcription, None
|
||||
if audio_auto:
|
||||
return do_stt(audio, text_state)
|
||||
return "", ""
|
||||
|
||||
|
||||
def ui():
|
||||
tr_state = gr.State(value="")
|
||||
output_transcription = gr.Textbox(label="STT-Input",
|
||||
placeholder="Speech Preview. Click \"Generate\" to send",
|
||||
interactive=True)
|
||||
output_transcription.change(fn=update_hijack, inputs=[output_transcription], outputs=[tr_state])
|
||||
audio_auto = gr.Checkbox(label="Auto-Transcribe", value=True)
|
||||
with gr.Row():
|
||||
audio = gr.Audio(source="microphone")
|
||||
auto_submit = gr.Checkbox(label='Submit the transcribed audio automatically', value=True)
|
||||
audio.change(fn=auto_transcribe, inputs=[audio, auto_submit], outputs=[shared.gradio['textbox'], audio])
|
||||
audio.change(None, auto_submit, None, _js="(check) => {if (check) { document.getElementById('Generate').click() }}")
|
||||
audio.change(fn=auto_transcribe, inputs=[audio, audio_auto, tr_state], outputs=[output_transcription, tr_state])
|
||||
transcribe_button = gr.Button(value="Transcribe")
|
||||
transcribe_button.click(do_stt, inputs=[audio, tr_state], outputs=[output_transcription, tr_state])
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
import inspect
|
||||
import re
|
||||
import sys
|
||||
from pathlib import Path
|
||||
@@ -17,14 +16,12 @@ from quant import make_quant
|
||||
|
||||
|
||||
def _load_quant(model, checkpoint, wbits, groupsize=-1, faster_kernel=False, exclude_layers=['lm_head'], kernel_switch_threshold=128):
|
||||
|
||||
config = AutoConfig.from_pretrained(model)
|
||||
def noop(*args, **kwargs):
|
||||
pass
|
||||
|
||||
config = AutoConfig.from_pretrained(model)
|
||||
torch.nn.init.kaiming_uniform_ = noop
|
||||
torch.nn.init.uniform_ = noop
|
||||
torch.nn.init.normal_ = noop
|
||||
torch.nn.init.kaiming_uniform_ = noop
|
||||
torch.nn.init.uniform_ = noop
|
||||
torch.nn.init.normal_ = noop
|
||||
|
||||
torch.set_default_dtype(torch.half)
|
||||
transformers.modeling_utils._init_weights = False
|
||||
@@ -36,37 +33,21 @@ def _load_quant(model, checkpoint, wbits, groupsize=-1, faster_kernel=False, exc
|
||||
for name in exclude_layers:
|
||||
if name in layers:
|
||||
del layers[name]
|
||||
|
||||
gptq_args = inspect.getfullargspec(make_quant).args
|
||||
|
||||
make_quant_kwargs = {
|
||||
'module': model,
|
||||
'names': layers,
|
||||
'bits': wbits,
|
||||
}
|
||||
if 'groupsize' in gptq_args:
|
||||
make_quant_kwargs['groupsize'] = groupsize
|
||||
if 'faster' in gptq_args:
|
||||
make_quant_kwargs['faster'] = faster_kernel
|
||||
if 'kernel_switch_threshold' in gptq_args:
|
||||
make_quant_kwargs['kernel_switch_threshold'] = kernel_switch_threshold
|
||||
|
||||
make_quant(**make_quant_kwargs)
|
||||
make_quant(model, layers, wbits, groupsize, faster=faster_kernel, kernel_switch_threshold=kernel_switch_threshold)
|
||||
|
||||
del layers
|
||||
|
||||
|
||||
print('Loading model ...')
|
||||
if checkpoint.endswith('.safetensors'):
|
||||
from safetensors.torch import load_file as safe_load
|
||||
model.load_state_dict(safe_load(checkpoint), strict=False)
|
||||
model.load_state_dict(safe_load(checkpoint))
|
||||
else:
|
||||
model.load_state_dict(torch.load(checkpoint), strict=False)
|
||||
model.load_state_dict(torch.load(checkpoint))
|
||||
model.seqlen = 2048
|
||||
print('Done.')
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def load_quantized(model_name):
|
||||
if not shared.args.model_type:
|
||||
# Try to determine model type from model name
|
||||
@@ -100,10 +81,10 @@ def load_quantized(model_name):
|
||||
found_safetensors = list(path_to_model.glob("*.safetensors"))
|
||||
pt_path = None
|
||||
|
||||
if len(found_pts) > 0:
|
||||
pt_path = found_pts[-1]
|
||||
elif len(found_safetensors) > 0:
|
||||
pt_path = found_safetensors[-1]
|
||||
if len(found_pts) == 1:
|
||||
pt_path = found_pts[0]
|
||||
elif len(found_safetensors) == 1:
|
||||
pt_path = found_safetensors[0]
|
||||
else:
|
||||
if path_to_model.name.lower().startswith('llama-7b'):
|
||||
pt_model = f'llama-7b-{shared.args.wbits}bit'
|
||||
@@ -117,16 +98,15 @@ def load_quantized(model_name):
|
||||
pt_model = f'{model_name}-{shared.args.wbits}bit'
|
||||
|
||||
# Try to find the .safetensors or .pt both in the model dir and in the subfolder
|
||||
for path in [Path(p + ext) for ext in ['.safetensors', '.pt'] for p in [f"{shared.args.model_dir}/{pt_model}", f"{path_to_model}/{pt_model}"]]:
|
||||
for path in [Path(p+ext) for ext in ['.safetensors', '.pt'] for p in [f"{shared.args.model_dir}/{pt_model}", f"{path_to_model}/{pt_model}"]]:
|
||||
if path.exists():
|
||||
print(f"Found {path}")
|
||||
pt_path = path
|
||||
break
|
||||
|
||||
if not pt_path:
|
||||
print("Could not find the quantized model in .pt or .safetensors format, exiting...")
|
||||
exit()
|
||||
else:
|
||||
print(f"Found the following quantized model: {pt_path}")
|
||||
|
||||
# qwopqwop200's offload
|
||||
if model_type == 'llama' and shared.args.pre_layer:
|
||||
@@ -137,7 +117,7 @@ def load_quantized(model_name):
|
||||
|
||||
# accelerate offload (doesn't work properly)
|
||||
if shared.args.gpu_memory:
|
||||
memory_map = list(map(lambda x: x.strip(), shared.args.gpu_memory))
|
||||
memory_map = list(map(lambda x : x.strip(), shared.args.gpu_memory))
|
||||
max_cpu_memory = shared.args.cpu_memory.strip() if shared.args.cpu_memory is not None else '99GiB'
|
||||
max_memory = {}
|
||||
for i in range(len(memory_map)):
|
||||
|
||||
@@ -4,9 +4,15 @@ import torch
|
||||
from peft import PeftModel
|
||||
|
||||
import modules.shared as shared
|
||||
from modules.models import reload_model
|
||||
from modules.models import load_model
|
||||
from modules.text_generation import clear_torch_cache
|
||||
|
||||
|
||||
def reload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
shared.model, shared.tokenizer = load_model(shared.model_name)
|
||||
|
||||
def add_lora_to_model(lora_name):
|
||||
|
||||
# If a LoRA had been previously loaded, or if we want
|
||||
@@ -21,10 +27,10 @@ def add_lora_to_model(lora_name):
|
||||
if not shared.args.cpu:
|
||||
params['dtype'] = shared.model.dtype
|
||||
if hasattr(shared.model, "hf_device_map"):
|
||||
params['device_map'] = {"base_model.model." + k: v for k, v in shared.model.hf_device_map.items()}
|
||||
params['device_map'] = {"base_model.model."+k: v for k, v in shared.model.hf_device_map.items()}
|
||||
elif shared.args.load_in_8bit:
|
||||
params['device_map'] = {'': 0}
|
||||
|
||||
|
||||
shared.model = PeftModel.from_pretrained(shared.model, Path(f"{shared.args.lora_dir}/{lora_name}"), **params)
|
||||
if not shared.args.load_in_8bit and not shared.args.cpu:
|
||||
shared.model.half()
|
||||
|
||||
@@ -10,7 +10,7 @@ from modules.callbacks import Iteratorize
|
||||
np.set_printoptions(precision=4, suppress=True, linewidth=200)
|
||||
|
||||
os.environ['RWKV_JIT_ON'] = '1'
|
||||
os.environ["RWKV_CUDA_ON"] = '1' if shared.args.rwkv_cuda_on else '0' # use CUDA kernel for seq mode (much faster)
|
||||
os.environ["RWKV_CUDA_ON"] = '1' if shared.args.rwkv_cuda_on else '0' # use CUDA kernel for seq mode (much faster)
|
||||
|
||||
from rwkv.model import RWKV
|
||||
from rwkv.utils import PIPELINE, PIPELINE_ARGS
|
||||
@@ -36,13 +36,13 @@ class RWKVModel:
|
||||
|
||||
def generate(self, context="", token_count=20, temperature=1, top_p=1, top_k=50, repetition_penalty=None, alpha_frequency=0.1, alpha_presence=0.1, token_ban=[0], token_stop=[], callback=None):
|
||||
args = PIPELINE_ARGS(
|
||||
temperature=temperature,
|
||||
top_p=top_p,
|
||||
top_k=top_k,
|
||||
alpha_frequency=alpha_frequency, # Frequency Penalty (as in GPT-3)
|
||||
alpha_presence=alpha_presence, # Presence Penalty (as in GPT-3)
|
||||
token_ban=token_ban, # ban the generation of some tokens
|
||||
token_stop=token_stop
|
||||
temperature = temperature,
|
||||
top_p = top_p,
|
||||
top_k = top_k,
|
||||
alpha_frequency = alpha_frequency, # Frequency Penalty (as in GPT-3)
|
||||
alpha_presence = alpha_presence, # Presence Penalty (as in GPT-3)
|
||||
token_ban = token_ban, # ban the generation of some tokens
|
||||
token_stop = token_stop
|
||||
)
|
||||
|
||||
return self.pipeline.generate(context, token_count=token_count, args=args, callback=callback)
|
||||
@@ -54,7 +54,6 @@ class RWKVModel:
|
||||
reply += token
|
||||
yield reply
|
||||
|
||||
|
||||
class RWKVTokenizer:
|
||||
def __init__(self):
|
||||
pass
|
||||
|
||||
@@ -28,7 +28,6 @@ def generate_reply_wrapper(string):
|
||||
for i in generate_reply(params[0], generate_params):
|
||||
yield i
|
||||
|
||||
|
||||
def create_apis():
|
||||
t1 = gr.Textbox(visible=False)
|
||||
t2 = gr.Textbox(visible=False)
|
||||
|
||||
@@ -30,7 +30,6 @@ class _SentinelTokenStoppingCriteria(transformers.StoppingCriteria):
|
||||
return True
|
||||
return False
|
||||
|
||||
|
||||
class Stream(transformers.StoppingCriteria):
|
||||
def __init__(self, callback_func=None):
|
||||
self.callback_func = callback_func
|
||||
@@ -40,7 +39,6 @@ class Stream(transformers.StoppingCriteria):
|
||||
self.callback_func(input_ids[0])
|
||||
return False
|
||||
|
||||
|
||||
class Iteratorize:
|
||||
|
||||
"""
|
||||
@@ -49,8 +47,8 @@ class Iteratorize:
|
||||
"""
|
||||
|
||||
def __init__(self, func, kwargs={}, callback=None):
|
||||
self.mfunc = func
|
||||
self.c_callback = callback
|
||||
self.mfunc=func
|
||||
self.c_callback=callback
|
||||
self.q = Queue()
|
||||
self.sentinel = object()
|
||||
self.kwargs = kwargs
|
||||
@@ -82,7 +80,7 @@ class Iteratorize:
|
||||
return self
|
||||
|
||||
def __next__(self):
|
||||
obj = self.q.get(True, None)
|
||||
obj = self.q.get(True,None)
|
||||
if obj is self.sentinel:
|
||||
raise StopIteration
|
||||
else:
|
||||
@@ -98,7 +96,6 @@ class Iteratorize:
|
||||
self.stop_now = True
|
||||
clear_torch_cache()
|
||||
|
||||
|
||||
def clear_torch_cache():
|
||||
gc.collect()
|
||||
if not shared.args.cpu:
|
||||
|
||||
189
modules/chat.py
189
modules/chat.py
@@ -12,7 +12,7 @@ from PIL import Image
|
||||
import modules.extensions as extensions_module
|
||||
import modules.shared as shared
|
||||
from modules.extensions import apply_extensions
|
||||
from modules.html_generator import (chat_html_wrapper, fix_newlines,
|
||||
from modules.html_generator import (fix_newlines, chat_html_wrapper,
|
||||
make_thumbnail)
|
||||
from modules.text_generation import (encode, generate_reply,
|
||||
get_max_prompt_length)
|
||||
@@ -22,13 +22,14 @@ def generate_chat_prompt(user_input, max_new_tokens, name1, name2, context, chat
|
||||
is_instruct = kwargs['is_instruct'] if 'is_instruct' in kwargs else False
|
||||
end_of_turn = kwargs['end_of_turn'] if 'end_of_turn' in kwargs else ''
|
||||
impersonate = kwargs['impersonate'] if 'impersonate' in kwargs else False
|
||||
_continue = kwargs['_continue'] if '_continue' in kwargs else False
|
||||
also_return_rows = kwargs['also_return_rows'] if 'also_return_rows' in kwargs else False
|
||||
|
||||
user_input = fix_newlines(user_input)
|
||||
rows = [f"{context.strip()}\n"]
|
||||
|
||||
# Finding the maximum prompt size
|
||||
if shared.soft_prompt:
|
||||
chat_prompt_size -= shared.soft_prompt_tensor.shape[1]
|
||||
chat_prompt_size -= shared.soft_prompt_tensor.shape[1]
|
||||
max_length = min(get_max_prompt_length(max_new_tokens), chat_prompt_size)
|
||||
|
||||
if is_instruct:
|
||||
@@ -38,12 +39,9 @@ def generate_chat_prompt(user_input, max_new_tokens, name1, name2, context, chat
|
||||
prefix1 = f"{name1}: "
|
||||
prefix2 = f"{name2}: "
|
||||
|
||||
i = len(shared.history['internal']) - 1
|
||||
i = len(shared.history['internal'])-1
|
||||
while i >= 0 and len(encode(''.join(rows), max_new_tokens)[0]) < max_length:
|
||||
if _continue and i == len(shared.history['internal']) - 1:
|
||||
rows.insert(1, f"{prefix2}{shared.history['internal'][i][1]}")
|
||||
else:
|
||||
rows.insert(1, f"{prefix2}{shared.history['internal'][i][1].strip()}{end_of_turn}\n")
|
||||
rows.insert(1, f"{prefix2}{shared.history['internal'][i][1].strip()}{end_of_turn}\n")
|
||||
string = shared.history['internal'][i][0]
|
||||
if string not in ['', '<|BEGIN-VISIBLE-CHAT|>']:
|
||||
rows.insert(1, f"{prefix1}{string.strip()}{end_of_turn}\n")
|
||||
@@ -52,11 +50,9 @@ def generate_chat_prompt(user_input, max_new_tokens, name1, name2, context, chat
|
||||
if impersonate:
|
||||
rows.append(f"{prefix1.strip() if not is_instruct else prefix1}")
|
||||
limit = 2
|
||||
elif _continue:
|
||||
limit = 3
|
||||
else:
|
||||
|
||||
# Adding the user message
|
||||
user_input = fix_newlines(user_input)
|
||||
if len(user_input) > 0:
|
||||
rows.append(f"{prefix1}{user_input}{end_of_turn}\n")
|
||||
|
||||
@@ -73,7 +69,6 @@ def generate_chat_prompt(user_input, max_new_tokens, name1, name2, context, chat
|
||||
else:
|
||||
return prompt
|
||||
|
||||
|
||||
def extract_message_from_reply(reply, name1, name2, stop_at_newline):
|
||||
next_character_found = False
|
||||
|
||||
@@ -93,37 +88,26 @@ def extract_message_from_reply(reply, name1, name2, stop_at_newline):
|
||||
# is completed, trim it
|
||||
if not next_character_found:
|
||||
for string in [f"\n{name1}:", f"\n{name2}:"]:
|
||||
for j in range(len(string) - 1, 0, -1):
|
||||
for j in range(len(string)-1, 0, -1):
|
||||
if reply[-j:] == string[:j]:
|
||||
reply = reply[:-j]
|
||||
break
|
||||
else:
|
||||
continue
|
||||
break
|
||||
|
||||
reply = fix_newlines(reply)
|
||||
return reply, next_character_found
|
||||
|
||||
|
||||
def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn, regenerate=False, _continue=False):
|
||||
if mode == 'instruct':
|
||||
stopping_strings = [f"\n{name1}", f"\n{name2}"]
|
||||
else:
|
||||
stopping_strings = [f"\n{name1}:", f"\n{name2}:"]
|
||||
|
||||
# Defining some variables
|
||||
cumulative_reply = ''
|
||||
last_reply = [shared.history['internal'][-1][1], shared.history['visible'][-1][1]] if _continue else None
|
||||
def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn, regenerate=False):
|
||||
just_started = True
|
||||
name1_original = name1
|
||||
visible_text = custom_generate_chat_prompt = None
|
||||
eos_token = '\n' if generate_state['stop_at_newline'] else None
|
||||
name1_original = name1
|
||||
if 'pygmalion' in shared.model_name.lower():
|
||||
name1 = "You"
|
||||
|
||||
# Check if any extension wants to hijack this function call
|
||||
visible_text = None
|
||||
custom_generate_chat_prompt = None
|
||||
for extension, _ in extensions_module.iterator():
|
||||
if hasattr(extension, 'input_hijack') and extension.input_hijack['state']:
|
||||
if hasattr(extension, 'input_hijack') and extension.input_hijack['state'] == True:
|
||||
extension.input_hijack['state'] = False
|
||||
text, visible_text = extension.input_hijack['value']
|
||||
if custom_generate_chat_prompt is None and hasattr(extension, 'custom_generate_chat_prompt'):
|
||||
@@ -131,28 +115,23 @@ def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_tu
|
||||
|
||||
if visible_text is None:
|
||||
visible_text = text
|
||||
if not _continue:
|
||||
text = apply_extensions(text, "input")
|
||||
text = apply_extensions(text, "input")
|
||||
|
||||
# Generating the prompt
|
||||
kwargs = {
|
||||
'end_of_turn': end_of_turn,
|
||||
'is_instruct': mode == 'instruct',
|
||||
'_continue': _continue
|
||||
}
|
||||
kwargs = {'end_of_turn': end_of_turn, 'is_instruct': mode == 'instruct'}
|
||||
if custom_generate_chat_prompt is None:
|
||||
prompt = generate_chat_prompt(text, generate_state['max_new_tokens'], name1, name2, context, generate_state['chat_prompt_size'], **kwargs)
|
||||
else:
|
||||
prompt = custom_generate_chat_prompt(text, generate_state['max_new_tokens'], name1, name2, context, generate_state['chat_prompt_size'], **kwargs)
|
||||
|
||||
# Yield *Is typing...*
|
||||
if not any((regenerate, _continue)):
|
||||
yield shared.history['visible'] + [[visible_text, shared.processing_message]]
|
||||
if not regenerate:
|
||||
yield shared.history['visible']+[[visible_text, shared.processing_message]]
|
||||
|
||||
# Generate
|
||||
cumulative_reply = ''
|
||||
for i in range(generate_state['chat_generation_attempts']):
|
||||
reply = None
|
||||
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=stopping_strings):
|
||||
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=[f"\n{name1}:", f"\n{name2}:"]):
|
||||
reply = cumulative_reply + reply
|
||||
|
||||
# Extracting the reply
|
||||
@@ -166,17 +145,11 @@ def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_tu
|
||||
return shared.history['visible']
|
||||
if just_started:
|
||||
just_started = False
|
||||
if not _continue:
|
||||
shared.history['internal'].append(['', ''])
|
||||
shared.history['visible'].append(['', ''])
|
||||
shared.history['internal'].append(['', ''])
|
||||
shared.history['visible'].append(['', ''])
|
||||
|
||||
if _continue:
|
||||
sep = list(map(lambda x : ' ' if x[-1] != ' ' else '', last_reply))
|
||||
shared.history['internal'][-1] = [text, f'{last_reply[0]}{sep[0]}{reply}']
|
||||
shared.history['visible'][-1] = [visible_text, f'{last_reply[1]}{sep[1]}{visible_reply}']
|
||||
else:
|
||||
shared.history['internal'][-1] = [text, reply]
|
||||
shared.history['visible'][-1] = [visible_text, visible_reply]
|
||||
shared.history['internal'][-1] = [text, reply]
|
||||
shared.history['visible'][-1] = [visible_text, visible_reply]
|
||||
if not shared.args.no_stream:
|
||||
yield shared.history['visible']
|
||||
if next_character_found:
|
||||
@@ -187,16 +160,9 @@ def chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_tu
|
||||
|
||||
yield shared.history['visible']
|
||||
|
||||
|
||||
def impersonate_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
||||
if mode == 'instruct':
|
||||
stopping_strings = [f"\n{name1}", f"\n{name2}"]
|
||||
else:
|
||||
stopping_strings = [f"\n{name1}:", f"\n{name2}:"]
|
||||
|
||||
# Defining some variables
|
||||
cumulative_reply = ''
|
||||
eos_token = '\n' if generate_state['stop_at_newline'] else None
|
||||
|
||||
if 'pygmalion' in shared.model_name.lower():
|
||||
name1 = "You"
|
||||
|
||||
@@ -205,9 +171,10 @@ def impersonate_wrapper(text, generate_state, name1, name2, context, mode, end_o
|
||||
# Yield *Is typing...*
|
||||
yield shared.processing_message
|
||||
|
||||
cumulative_reply = ''
|
||||
for i in range(generate_state['chat_generation_attempts']):
|
||||
reply = None
|
||||
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=stopping_strings):
|
||||
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", generate_state, eos_token=eos_token, stopping_strings=[f"\n{name1}:", f"\n{name2}:"]):
|
||||
reply = cumulative_reply + reply
|
||||
reply, next_character_found = extract_message_from_reply(reply, name1, name2, generate_state['stop_at_newline'])
|
||||
yield reply
|
||||
@@ -219,35 +186,22 @@ def impersonate_wrapper(text, generate_state, name1, name2, context, mode, end_o
|
||||
|
||||
yield reply
|
||||
|
||||
|
||||
def cai_chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
||||
for history in chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
||||
for history in chatbot_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn, regenerate=False):
|
||||
yield chat_html_wrapper(history, name1, name2, mode)
|
||||
|
||||
|
||||
def regenerate_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
||||
if (len(shared.history['visible']) == 1 and not shared.history['visible'][0][0]) or len(shared.history['internal']) == 0:
|
||||
if (shared.character != 'None' and len(shared.history['visible']) == 1) or len(shared.history['internal']) == 0:
|
||||
yield chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
else:
|
||||
last_visible = shared.history['visible'].pop()
|
||||
last_internal = shared.history['internal'].pop()
|
||||
# Yield '*Is typing...*'
|
||||
yield chat_html_wrapper(shared.history['visible'] + [[last_visible[0], shared.processing_message]], name1, name2, mode)
|
||||
yield chat_html_wrapper(shared.history['visible']+[[last_visible[0], shared.processing_message]], name1, name2, mode)
|
||||
for history in chatbot_wrapper(last_internal[0], generate_state, name1, name2, context, mode, end_of_turn, regenerate=True):
|
||||
shared.history['visible'][-1] = [last_visible[0], history[-1][1]]
|
||||
yield chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
|
||||
|
||||
def continue_wrapper(text, generate_state, name1, name2, context, mode, end_of_turn):
|
||||
if (len(shared.history['visible']) == 1 and not shared.history['visible'][0][0]) or len(shared.history['internal']) == 0:
|
||||
yield chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
else:
|
||||
# Yield ' ...'
|
||||
yield chat_html_wrapper(shared.history['visible'][:-1] + [[shared.history['visible'][-1][0], shared.history['visible'][-1][1] + ' ...']], name1, name2, mode)
|
||||
for history in chatbot_wrapper(shared.history['internal'][-1][0], generate_state, name1, name2, context, mode, end_of_turn, _continue=True):
|
||||
yield chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
|
||||
|
||||
def remove_last_message(name1, name2, mode):
|
||||
if len(shared.history['visible']) > 0 and shared.history['internal'][-1][0] != '<|BEGIN-VISIBLE-CHAT|>':
|
||||
last = shared.history['visible'].pop()
|
||||
@@ -257,14 +211,12 @@ def remove_last_message(name1, name2, mode):
|
||||
|
||||
return chat_html_wrapper(shared.history['visible'], name1, name2, mode), last[0]
|
||||
|
||||
|
||||
def send_last_reply_to_input():
|
||||
if len(shared.history['internal']) > 0:
|
||||
return shared.history['internal'][-1][1]
|
||||
else:
|
||||
return ''
|
||||
|
||||
|
||||
def replace_last_reply(text, name1, name2, mode):
|
||||
if len(shared.history['visible']) > 0:
|
||||
shared.history['visible'][-1][1] = text
|
||||
@@ -272,11 +224,9 @@ def replace_last_reply(text, name1, name2, mode):
|
||||
|
||||
return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
|
||||
|
||||
def clear_html():
|
||||
return chat_html_wrapper([], "", "")
|
||||
|
||||
|
||||
def clear_chat_log(name1, name2, greeting, mode):
|
||||
shared.history['visible'] = []
|
||||
shared.history['internal'] = []
|
||||
@@ -284,20 +234,15 @@ def clear_chat_log(name1, name2, greeting, mode):
|
||||
if greeting != '':
|
||||
shared.history['internal'] += [['<|BEGIN-VISIBLE-CHAT|>', greeting]]
|
||||
shared.history['visible'] += [['', apply_extensions(greeting, "output")]]
|
||||
|
||||
# Save cleared logs
|
||||
save_history(mode)
|
||||
|
||||
return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
|
||||
|
||||
def redraw_html(name1, name2, mode):
|
||||
return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
|
||||
|
||||
def tokenize_dialogue(dialogue, name1, name2, mode):
|
||||
history = []
|
||||
messages = []
|
||||
|
||||
dialogue = re.sub('<START>', '', dialogue)
|
||||
dialogue = re.sub('<start>', '', dialogue)
|
||||
dialogue = re.sub('(\n|^)[Aa]non:', '\\1You:', dialogue)
|
||||
@@ -306,8 +251,9 @@ def tokenize_dialogue(dialogue, name1, name2, mode):
|
||||
if len(idx) == 0:
|
||||
return history
|
||||
|
||||
for i in range(len(idx) - 1):
|
||||
messages.append(dialogue[idx[i]:idx[i + 1]].strip())
|
||||
messages = []
|
||||
for i in range(len(idx)-1):
|
||||
messages.append(dialogue[idx[i]:idx[i+1]].strip())
|
||||
messages.append(dialogue[idx[-1]:].strip())
|
||||
|
||||
entry = ['', '']
|
||||
@@ -325,33 +271,23 @@ def tokenize_dialogue(dialogue, name1, name2, mode):
|
||||
for column in row:
|
||||
print("\n")
|
||||
for line in column.strip().split('\n'):
|
||||
print("| " + line + "\n")
|
||||
print("| "+line+"\n")
|
||||
print("|\n")
|
||||
print("------------------------------")
|
||||
|
||||
return history
|
||||
|
||||
|
||||
def save_history(mode, timestamp=False):
|
||||
# Instruct mode histories should not be saved as if
|
||||
# Alpaca or Vicuna were characters
|
||||
if mode == 'instruct':
|
||||
if not timestamp:
|
||||
return
|
||||
fname = f"Instruct_{datetime.now().strftime('%Y%m%d-%H%M%S')}.json"
|
||||
def save_history(timestamp=True):
|
||||
if timestamp:
|
||||
fname = f"{shared.character}_{datetime.now().strftime('%Y%m%d-%H%M%S')}.json"
|
||||
else:
|
||||
if timestamp:
|
||||
fname = f"{shared.character}_{datetime.now().strftime('%Y%m%d-%H%M%S')}.json"
|
||||
else:
|
||||
fname = f"{shared.character}_persistent.json"
|
||||
fname = f"{shared.character}_persistent.json"
|
||||
if not Path('logs').exists():
|
||||
Path('logs').mkdir()
|
||||
with open(Path(f'logs/{fname}'), 'w', encoding='utf-8') as f:
|
||||
f.write(json.dumps({'data': shared.history['internal'], 'data_visible': shared.history['visible']}, indent=2))
|
||||
|
||||
return Path(f'logs/{fname}')
|
||||
|
||||
|
||||
def load_history(file, name1, name2):
|
||||
file = file.decode('utf-8')
|
||||
try:
|
||||
@@ -362,16 +298,24 @@ def load_history(file, name1, name2):
|
||||
shared.history['visible'] = j['data_visible']
|
||||
else:
|
||||
shared.history['visible'] = copy.deepcopy(shared.history['internal'])
|
||||
# Compatibility with Pygmalion AI's official web UI
|
||||
elif 'chat' in j:
|
||||
shared.history['internal'] = [':'.join(x.split(':')[1:]).strip() for x in j['chat']]
|
||||
if len(j['chat']) > 0 and j['chat'][0].startswith(f'{name2}:'):
|
||||
shared.history['internal'] = [['<|BEGIN-VISIBLE-CHAT|>', shared.history['internal'][0]]] + [[shared.history['internal'][i], shared.history['internal'][i+1]] for i in range(1, len(shared.history['internal'])-1, 2)]
|
||||
shared.history['visible'] = copy.deepcopy(shared.history['internal'])
|
||||
shared.history['visible'][0][0] = ''
|
||||
else:
|
||||
shared.history['internal'] = [[shared.history['internal'][i], shared.history['internal'][i+1]] for i in range(0, len(shared.history['internal'])-1, 2)]
|
||||
shared.history['visible'] = copy.deepcopy(shared.history['internal'])
|
||||
except:
|
||||
shared.history['internal'] = tokenize_dialogue(file, name1, name2)
|
||||
shared.history['visible'] = copy.deepcopy(shared.history['internal'])
|
||||
|
||||
|
||||
def replace_character_names(text, name1, name2):
|
||||
text = text.replace('{{user}}', name1).replace('{{char}}', name2)
|
||||
return text.replace('<USER>', name1).replace('<BOT>', name2)
|
||||
|
||||
|
||||
def build_pygmalion_style_context(data):
|
||||
context = ""
|
||||
if 'char_persona' in data and data['char_persona'] != '':
|
||||
@@ -381,7 +325,6 @@ def build_pygmalion_style_context(data):
|
||||
context = f"{context.strip()}\n<START>\n"
|
||||
return context
|
||||
|
||||
|
||||
def generate_pfp_cache(character):
|
||||
cache_folder = Path("cache")
|
||||
if not cache_folder.exists():
|
||||
@@ -394,9 +337,10 @@ def generate_pfp_cache(character):
|
||||
return img
|
||||
return None
|
||||
|
||||
|
||||
def load_character(character, name1, name2, mode):
|
||||
shared.character = character
|
||||
shared.history['internal'] = []
|
||||
shared.history['visible'] = []
|
||||
context = greeting = end_of_turn = ""
|
||||
greeting_field = 'greeting'
|
||||
picture = None
|
||||
@@ -432,37 +376,26 @@ def load_character(character, name1, name2, mode):
|
||||
if 'example_dialogue' in data:
|
||||
context += f"{data['example_dialogue'].strip()}\n"
|
||||
if greeting_field in data:
|
||||
greeting = data[greeting_field]
|
||||
greeting = data[greeting_field]
|
||||
if 'end_of_turn' in data:
|
||||
end_of_turn = data['end_of_turn']
|
||||
end_of_turn = data['end_of_turn']
|
||||
else:
|
||||
context = shared.settings['context']
|
||||
name2 = shared.settings['name2']
|
||||
greeting = shared.settings['greeting']
|
||||
greeting = shared.settings['greeting']
|
||||
end_of_turn = shared.settings['end_of_turn']
|
||||
|
||||
if mode != 'instruct':
|
||||
shared.history['internal'] = []
|
||||
shared.history['visible'] = []
|
||||
|
||||
if Path(f'logs/{shared.character}_persistent.json').exists():
|
||||
load_history(open(Path(f'logs/{shared.character}_persistent.json'), 'rb').read(), name1, name2)
|
||||
else:
|
||||
# Insert greeting if it exists
|
||||
if greeting != "":
|
||||
shared.history['internal'] += [['<|BEGIN-VISIBLE-CHAT|>', greeting]]
|
||||
shared.history['visible'] += [['', apply_extensions(greeting, "output")]]
|
||||
|
||||
# Create .json log files since they don't already exist
|
||||
save_history(mode)
|
||||
|
||||
return name1, name2, picture, greeting, context, end_of_turn, chat_html_wrapper(shared.history['visible'], name1, name2, mode)
|
||||
if Path(f'logs/{shared.character}_persistent.json').exists():
|
||||
load_history(open(Path(f'logs/{shared.character}_persistent.json'), 'rb').read(), name1, name2)
|
||||
elif greeting != "":
|
||||
shared.history['internal'] += [['<|BEGIN-VISIBLE-CHAT|>', greeting]]
|
||||
shared.history['visible'] += [['', apply_extensions(greeting, "output")]]
|
||||
|
||||
return name1, name2, picture, greeting, context, end_of_turn, chat_html_wrapper(shared.history['visible'], name1, name2, mode, reset_cache=True)
|
||||
|
||||
def load_default_history(name1, name2):
|
||||
load_character("None", name1, name2, "chat")
|
||||
|
||||
|
||||
def upload_character(json_file, img, tavern=False):
|
||||
json_file = json_file if type(json_file) == str else json_file.decode('utf-8')
|
||||
data = json.loads(json_file)
|
||||
@@ -481,7 +414,6 @@ def upload_character(json_file, img, tavern=False):
|
||||
print(f'New character saved to "characters/{outfile_name}.json".')
|
||||
return outfile_name
|
||||
|
||||
|
||||
def upload_tavern_character(img, name1, name2):
|
||||
_img = Image.open(io.BytesIO(img))
|
||||
_img.getexif()
|
||||
@@ -490,13 +422,12 @@ def upload_tavern_character(img, name1, name2):
|
||||
_json = {"char_name": _json['name'], "char_persona": _json['description'], "char_greeting": _json["first_mes"], "example_dialogue": _json['mes_example'], "world_scenario": _json['scenario']}
|
||||
return upload_character(json.dumps(_json), img, tavern=True)
|
||||
|
||||
|
||||
def upload_your_profile_picture(img, name1, name2, mode):
|
||||
cache_folder = Path("cache")
|
||||
if not cache_folder.exists():
|
||||
cache_folder.mkdir()
|
||||
|
||||
if img is None:
|
||||
if img == None:
|
||||
if Path("cache/pfp_me.png").exists():
|
||||
Path("cache/pfp_me.png").unlink()
|
||||
else:
|
||||
|
||||
@@ -9,32 +9,25 @@ state = {}
|
||||
available_extensions = []
|
||||
setup_called = set()
|
||||
|
||||
|
||||
def load_extensions():
|
||||
global state, setup_called
|
||||
global state
|
||||
for i, name in enumerate(shared.args.extensions):
|
||||
if name in available_extensions:
|
||||
print(f'Loading the extension "{name}"... ', end='')
|
||||
try:
|
||||
exec(f"import extensions.{name}.script")
|
||||
extension = eval(f"extensions.{name}.script")
|
||||
if extension not in setup_called and hasattr(extension, "setup"):
|
||||
setup_called.add(extension)
|
||||
extension.setup()
|
||||
state[name] = [True, i]
|
||||
print('Ok.')
|
||||
except:
|
||||
print('Fail.')
|
||||
traceback.print_exc()
|
||||
|
||||
|
||||
# This iterator returns the extensions in the order specified in the command-line
|
||||
def iterator():
|
||||
for name in sorted(state, key=lambda x: state[x][1]):
|
||||
if state[name][0]:
|
||||
for name in sorted(state, key=lambda x : state[x][1]):
|
||||
if state[name][0] == True:
|
||||
yield eval(f"extensions.{name}.script"), name
|
||||
|
||||
|
||||
# Extension functions that map string -> string
|
||||
def apply_extensions(text, typ):
|
||||
for extension, _ in iterator():
|
||||
@@ -46,7 +39,6 @@ def apply_extensions(text, typ):
|
||||
text = extension.bot_prefix_modifier(text)
|
||||
return text
|
||||
|
||||
|
||||
def create_extensions_block():
|
||||
global setup_called
|
||||
|
||||
@@ -59,9 +51,14 @@ def create_extensions_block():
|
||||
extension.params[param] = shared.settings[_id]
|
||||
|
||||
should_display_ui = False
|
||||
|
||||
# Running setup function
|
||||
for extension, name in iterator():
|
||||
if hasattr(extension, "ui"):
|
||||
should_display_ui = True
|
||||
if extension not in setup_called and hasattr(extension, "setup"):
|
||||
setup_called.add(extension)
|
||||
extension.setup()
|
||||
|
||||
# Creating the extension ui elements
|
||||
if should_display_ui:
|
||||
|
||||
@@ -24,7 +24,6 @@ with open(Path(__file__).resolve().parent / '../css/html_cai_style.css', 'r') as
|
||||
with open(Path(__file__).resolve().parent / '../css/html_instruct_style.css', 'r') as f:
|
||||
instruct_css = f.read()
|
||||
|
||||
|
||||
def fix_newlines(string):
|
||||
string = string.replace('\n', '\n\n')
|
||||
string = re.sub(r"\n{3,}", "\n\n", string)
|
||||
@@ -32,8 +31,6 @@ def fix_newlines(string):
|
||||
return string
|
||||
|
||||
# This could probably be generalized and improved
|
||||
|
||||
|
||||
def convert_to_markdown(string):
|
||||
string = string.replace('\\begin{code}', '```')
|
||||
string = string.replace('\\end{code}', '```')
|
||||
@@ -41,15 +38,13 @@ def convert_to_markdown(string):
|
||||
string = string.replace('\\end{blockquote}', '')
|
||||
string = re.sub(r"(.)```", r"\1\n```", string)
|
||||
string = fix_newlines(string)
|
||||
return markdown.markdown(string, extensions=['fenced_code'])
|
||||
|
||||
return markdown.markdown(string, extensions=['fenced_code'])
|
||||
|
||||
def generate_basic_html(string):
|
||||
string = convert_to_markdown(string)
|
||||
string = f'<style>{readable_css}</style><div class="container">{string}</div>'
|
||||
return string
|
||||
|
||||
|
||||
def process_post(post, c):
|
||||
t = post.split('\n')
|
||||
number = t[0].split(' ')[1]
|
||||
@@ -64,7 +59,6 @@ def process_post(post, c):
|
||||
src = f'<span class="name">Anonymous </span> <span class="number">No.{number}</span>\n{src}'
|
||||
return src
|
||||
|
||||
|
||||
def generate_4chan_html(f):
|
||||
posts = []
|
||||
post = ''
|
||||
@@ -90,7 +84,7 @@ def generate_4chan_html(f):
|
||||
posts[i] = f'<div class="op">{posts[i]}</div>\n'
|
||||
else:
|
||||
posts[i] = f'<div class="reply">{posts[i]}</div>\n'
|
||||
|
||||
|
||||
output = ''
|
||||
output += f'<style>{_4chan_css}</style><div id="parent"><div id="container">'
|
||||
for post in posts:
|
||||
@@ -104,15 +98,13 @@ def generate_4chan_html(f):
|
||||
|
||||
return output
|
||||
|
||||
|
||||
def make_thumbnail(image):
|
||||
image = image.resize((350, round(image.size[1] / image.size[0] * 350)), Image.Resampling.LANCZOS)
|
||||
image = image.resize((350, round(image.size[1]/image.size[0]*350)), Image.Resampling.LANCZOS)
|
||||
if image.size[1] > 470:
|
||||
image = ImageOps.fit(image, (350, 470), Image.ANTIALIAS)
|
||||
|
||||
return image
|
||||
|
||||
|
||||
def get_image_cache(path):
|
||||
cache_folder = Path("cache")
|
||||
if not cache_folder.exists():
|
||||
@@ -127,10 +119,9 @@ def get_image_cache(path):
|
||||
|
||||
return image_cache[path][1]
|
||||
|
||||
|
||||
def generate_instruct_html(history):
|
||||
output = f'<style>{instruct_css}</style><div class="chat" id="chat">'
|
||||
for i, _row in enumerate(history[::-1]):
|
||||
for i,_row in enumerate(history[::-1]):
|
||||
row = [convert_to_markdown(entry) for entry in _row]
|
||||
|
||||
output += f"""
|
||||
@@ -143,7 +134,7 @@ def generate_instruct_html(history):
|
||||
</div>
|
||||
"""
|
||||
|
||||
if len(row[0]) == 0: # don't display empty user messages
|
||||
if len(row[0]) == 0: # don't display empty user messages
|
||||
continue
|
||||
|
||||
output += f"""
|
||||
@@ -160,15 +151,15 @@ def generate_instruct_html(history):
|
||||
|
||||
return output
|
||||
|
||||
|
||||
def generate_cai_chat_html(history, name1, name2, reset_cache=False):
|
||||
output = f'<style>{cai_css}</style><div class="chat" id="chat">'
|
||||
|
||||
# We use ?name2 and ?time.time() to force the browser to reset caches
|
||||
img_bot = f'<img src="file/cache/pfp_character.png?{name2}">' if Path("cache/pfp_character.png").exists() else ''
|
||||
img_me = f'<img src="file/cache/pfp_me.png?{time.time() if reset_cache else ""}">' if Path("cache/pfp_me.png").exists() else ''
|
||||
# The time.time() is to prevent the brower from caching the image
|
||||
suffix = f"?{time.time()}" if reset_cache else f"?{name2}"
|
||||
img_bot = f'<img src="file/cache/pfp_character.png{suffix}">' if Path("cache/pfp_character.png").exists() else ''
|
||||
img_me = f'<img src="file/cache/pfp_me.png{suffix}">' if Path("cache/pfp_me.png").exists() else ''
|
||||
|
||||
for i, _row in enumerate(history[::-1]):
|
||||
for i,_row in enumerate(history[::-1]):
|
||||
row = [convert_to_markdown(entry) for entry in _row]
|
||||
|
||||
output += f"""
|
||||
@@ -187,7 +178,7 @@ def generate_cai_chat_html(history, name1, name2, reset_cache=False):
|
||||
</div>
|
||||
"""
|
||||
|
||||
if len(row[0]) == 0: # don't display empty user messages
|
||||
if len(row[0]) == 0: # don't display empty user messages
|
||||
continue
|
||||
|
||||
output += f"""
|
||||
@@ -209,11 +200,9 @@ def generate_cai_chat_html(history, name1, name2, reset_cache=False):
|
||||
output += "</div>"
|
||||
return output
|
||||
|
||||
|
||||
def generate_chat_html(history, name1, name2):
|
||||
return generate_cai_chat_html(history, name1, name2)
|
||||
|
||||
|
||||
def chat_html_wrapper(history, name1, name2, mode, reset_cache=False):
|
||||
if mode == "cai-chat":
|
||||
return generate_cai_chat_html(history, name1, name2, reset_cache)
|
||||
|
||||
@@ -1,176 +0,0 @@
|
||||
import math
|
||||
import sys
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import transformers.models.llama.modeling_llama
|
||||
|
||||
from typing import Optional
|
||||
from typing import Tuple
|
||||
|
||||
import modules.shared as shared
|
||||
|
||||
|
||||
if shared.args.xformers:
|
||||
try:
|
||||
import xformers.ops
|
||||
except Exception:
|
||||
print("🔴 xformers not found! Please install it before trying to use it.", file=sys.stderr)
|
||||
|
||||
|
||||
def hijack_llama_attention():
|
||||
if shared.args.xformers:
|
||||
transformers.models.llama.modeling_llama.LlamaAttention.forward = xformers_forward
|
||||
print("Replaced attention with xformers_attention")
|
||||
elif shared.args.sdp_attention:
|
||||
transformers.models.llama.modeling_llama.LlamaAttention.forward = sdp_attention_forward
|
||||
print("Replaced attention with sdp_attention")
|
||||
|
||||
|
||||
def xformers_forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
|
||||
kv_seq_len = key_states.shape[-2]
|
||||
if past_key_value is not None:
|
||||
kv_seq_len += past_key_value[0].shape[-2]
|
||||
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
||||
query_states, key_states = transformers.models.llama.modeling_llama.apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
||||
# [bsz, nh, t, hd]
|
||||
|
||||
if past_key_value is not None:
|
||||
# reuse k, v, self_attention
|
||||
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
||||
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
||||
|
||||
past_key_value = (key_states, value_states) if use_cache else None
|
||||
|
||||
#We only apply xformers optimizations if we don't need to output the whole attention matrix
|
||||
if not output_attentions:
|
||||
dtype = query_states.dtype
|
||||
|
||||
query_states = query_states.transpose(1, 2)
|
||||
key_states = key_states.transpose(1, 2)
|
||||
value_states = value_states.transpose(1, 2)
|
||||
|
||||
#This is a nasty hack. We know attention_mask in transformers is either LowerTriangular or all Zeros.
|
||||
#We therefore check if one element in the upper triangular portion is zero. If it is, then the mask is all zeros.
|
||||
if attention_mask is None or attention_mask[0, 0, 0, 1] == 0:
|
||||
# input and output should be of form (bsz, q_len, num_heads, head_dim)
|
||||
attn_output = xformers.ops.memory_efficient_attention(query_states, key_states, value_states, attn_bias=None)
|
||||
else:
|
||||
# input and output should be of form (bsz, q_len, num_heads, head_dim)
|
||||
attn_output = xformers.ops.memory_efficient_attention(query_states, key_states, value_states, attn_bias=xformers.ops.LowerTriangularMask())
|
||||
attn_weights = None
|
||||
else:
|
||||
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
||||
|
||||
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention weights should be of size {(bsz * self.num_heads, q_len, kv_seq_len)}, but is"
|
||||
f" {attn_weights.size()}"
|
||||
)
|
||||
|
||||
if attention_mask is not None:
|
||||
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
||||
)
|
||||
attn_weights = attn_weights + attention_mask
|
||||
attn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))
|
||||
|
||||
# upcast attention to fp32
|
||||
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
||||
attn_output = torch.matmul(attn_weights, value_states)
|
||||
|
||||
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
||||
raise ValueError(
|
||||
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
||||
f" {attn_output.size()}"
|
||||
)
|
||||
|
||||
attn_output = attn_output.transpose(1, 2)
|
||||
|
||||
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
||||
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
return attn_output, attn_weights, past_key_value
|
||||
|
||||
|
||||
def sdp_attention_forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
|
||||
kv_seq_len = key_states.shape[-2]
|
||||
if past_key_value is not None:
|
||||
kv_seq_len += past_key_value[0].shape[-2]
|
||||
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
||||
query_states, key_states = transformers.models.llama.modeling_llama.apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
||||
# [bsz, nh, t, hd]
|
||||
|
||||
if past_key_value is not None:
|
||||
# reuse k, v, self_attention
|
||||
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
||||
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
||||
|
||||
past_key_value = (key_states, value_states) if use_cache else None
|
||||
|
||||
#We only apply sdp attention if we don't need to output the whole attention matrix
|
||||
if not output_attentions:
|
||||
attn_output = torch.nn.functional.scaled_dot_product_attention(query_states, key_states, value_states, attn_mask=attention_mask, is_causal=False)
|
||||
attn_weights = None
|
||||
else:
|
||||
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
||||
|
||||
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention weights should be of size {(bsz * self.num_heads, q_len, kv_seq_len)}, but is"
|
||||
f" {attn_weights.size()}"
|
||||
)
|
||||
|
||||
if attention_mask is not None:
|
||||
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
||||
)
|
||||
attn_weights = attn_weights + attention_mask
|
||||
attn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))
|
||||
|
||||
# upcast attention to fp32
|
||||
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
||||
attn_output = torch.matmul(attn_weights, value_states)
|
||||
|
||||
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
||||
raise ValueError(
|
||||
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
||||
f" {attn_output.size()}"
|
||||
)
|
||||
|
||||
attn_output = attn_output.transpose(1, 2)
|
||||
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
||||
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
return attn_output, attn_weights, past_key_value
|
||||
@@ -50,9 +50,9 @@ class LlamaCppModel:
|
||||
params.top_k = top_k
|
||||
params.temp = temperature
|
||||
params.repeat_penalty = repetition_penalty
|
||||
# params.repeat_last_n = repeat_last_n
|
||||
#params.repeat_last_n = repeat_last_n
|
||||
|
||||
# self.model.params = params
|
||||
#self.model.params = params
|
||||
self.model.add_bos()
|
||||
self.model.update_input(context)
|
||||
|
||||
|
||||
@@ -1,63 +0,0 @@
|
||||
'''
|
||||
Based on
|
||||
https://github.com/abetlen/llama-cpp-python
|
||||
|
||||
Documentation:
|
||||
https://abetlen.github.io/llama-cpp-python/
|
||||
'''
|
||||
|
||||
from llama_cpp import Llama
|
||||
|
||||
from modules import shared
|
||||
from modules.callbacks import Iteratorize
|
||||
|
||||
|
||||
class LlamaCppModel:
|
||||
def __init__(self):
|
||||
self.initialized = False
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(self, path):
|
||||
result = self()
|
||||
|
||||
params = {
|
||||
'model_path': str(path),
|
||||
'n_ctx': 2048,
|
||||
'seed': 0,
|
||||
'n_threads': shared.args.threads or None
|
||||
}
|
||||
self.model = Llama(**params)
|
||||
|
||||
# This is ugly, but the model and the tokenizer are the same object in this library.
|
||||
return result, result
|
||||
|
||||
def encode(self, string):
|
||||
if type(string) is str:
|
||||
string = string.encode()
|
||||
return self.model.tokenize(string)
|
||||
|
||||
def generate(self, context="", token_count=20, temperature=1, top_p=1, top_k=50, repetition_penalty=1, callback=None):
|
||||
if type(context) is str:
|
||||
context = context.encode()
|
||||
tokens = self.model.tokenize(context)
|
||||
|
||||
output = b""
|
||||
count = 0
|
||||
for token in self.model.generate(tokens, top_k=top_k, top_p=top_p, temp=temperature, repeat_penalty=repetition_penalty):
|
||||
text = self.model.detokenize([token])
|
||||
output += text
|
||||
if callback:
|
||||
callback(text.decode())
|
||||
|
||||
count += 1
|
||||
if count >= token_count or (token == self.model.token_eos()):
|
||||
break
|
||||
|
||||
return output.decode()
|
||||
|
||||
def generate_with_streaming(self, **kwargs):
|
||||
with Iteratorize(self.generate, kwargs, callback=None) as generator:
|
||||
reply = ''
|
||||
for token in generator:
|
||||
reply += token
|
||||
yield reply
|
||||
@@ -1,4 +1,3 @@
|
||||
import gc
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
@@ -11,17 +10,17 @@ import torch
|
||||
import transformers
|
||||
from accelerate import infer_auto_device_map, init_empty_weights
|
||||
from transformers import (AutoConfig, AutoModelForCausalLM, AutoTokenizer,
|
||||
BitsAndBytesConfig, LlamaTokenizer)
|
||||
BitsAndBytesConfig)
|
||||
|
||||
import modules.shared as shared
|
||||
from modules import llama_attn_hijack
|
||||
|
||||
transformers.logging.set_verbosity_error()
|
||||
|
||||
local_rank = None
|
||||
|
||||
if shared.args.flexgen:
|
||||
from flexgen.flex_opt import CompressionConfig, ExecutionEnv, OptLM, Policy
|
||||
|
||||
local_rank = None
|
||||
if shared.args.deepspeed:
|
||||
import deepspeed
|
||||
from transformers.deepspeed import (HfDeepSpeedConfig,
|
||||
@@ -35,7 +34,7 @@ if shared.args.deepspeed:
|
||||
torch.cuda.set_device(local_rank)
|
||||
deepspeed.init_distributed()
|
||||
ds_config = generate_ds_config(shared.args.bf16, 1 * world_size, shared.args.nvme_offload_dir)
|
||||
dschf = HfDeepSpeedConfig(ds_config) # Keep this object alive for the Transformers integration
|
||||
dschf = HfDeepSpeedConfig(ds_config) # Keep this object alive for the Transformers integration
|
||||
|
||||
|
||||
def load_model(model_name):
|
||||
@@ -84,7 +83,7 @@ def load_model(model_name):
|
||||
elif shared.args.deepspeed:
|
||||
model = AutoModelForCausalLM.from_pretrained(Path(f"{shared.args.model_dir}/{shared.model_name}"), torch_dtype=torch.bfloat16 if shared.args.bf16 else torch.float16)
|
||||
model = deepspeed.initialize(model=model, config_params=ds_config, model_parameters=None, optimizer=None, lr_scheduler=None)[0]
|
||||
model.module.eval() # Inference
|
||||
model.module.eval() # Inference
|
||||
print(f"DeepSpeed ZeRO-3 is enabled: {is_deepspeed_zero3_enabled()}")
|
||||
|
||||
# RMKV model (not on HuggingFace)
|
||||
@@ -104,7 +103,7 @@ def load_model(model_name):
|
||||
|
||||
# llamacpp model
|
||||
elif shared.is_llamacpp:
|
||||
from modules.llamacpp_model_alternative import LlamaCppModel
|
||||
from modules.llamacpp_model import LlamaCppModel
|
||||
|
||||
model_file = list(Path(f'{shared.args.model_dir}/{model_name}').glob('ggml*.bin'))[0]
|
||||
print(f"llama.cpp weights detected: {model_file}\n")
|
||||
@@ -133,7 +132,7 @@ def load_model(model_name):
|
||||
params["torch_dtype"] = torch.float16
|
||||
|
||||
if shared.args.gpu_memory:
|
||||
memory_map = list(map(lambda x: x.strip(), shared.args.gpu_memory))
|
||||
memory_map = list(map(lambda x : x.strip(), shared.args.gpu_memory))
|
||||
max_cpu_memory = shared.args.cpu_memory.strip() if shared.args.cpu_memory is not None else '99GiB'
|
||||
max_memory = {}
|
||||
for i in range(len(memory_map)):
|
||||
@@ -141,13 +140,13 @@ def load_model(model_name):
|
||||
max_memory['cpu'] = max_cpu_memory
|
||||
params['max_memory'] = max_memory
|
||||
elif shared.args.auto_devices:
|
||||
total_mem = (torch.cuda.get_device_properties(0).total_memory / (1024 * 1024))
|
||||
suggestion = round((total_mem - 1000) / 1000) * 1000
|
||||
total_mem = (torch.cuda.get_device_properties(0).total_memory / (1024*1024))
|
||||
suggestion = round((total_mem-1000) / 1000) * 1000
|
||||
if total_mem - suggestion < 800:
|
||||
suggestion -= 1000
|
||||
suggestion = int(round(suggestion / 1000))
|
||||
suggestion = int(round(suggestion/1000))
|
||||
print(f"\033[1;32;1mAuto-assiging --gpu-memory {suggestion} for your GPU to try to prevent out-of-memory errors.\nYou can manually set other values.\033[0;37;0m")
|
||||
|
||||
|
||||
max_memory = {0: f'{suggestion}GiB', 'cpu': f'{shared.args.cpu_memory or 99}GiB'}
|
||||
params['max_memory'] = max_memory
|
||||
|
||||
@@ -162,31 +161,17 @@ def load_model(model_name):
|
||||
model = AutoModelForCausalLM.from_config(config)
|
||||
model.tie_weights()
|
||||
params['device_map'] = infer_auto_device_map(
|
||||
model,
|
||||
dtype=torch.int8,
|
||||
model,
|
||||
dtype=torch.int8,
|
||||
max_memory=params['max_memory'],
|
||||
no_split_module_classes=model._no_split_modules
|
||||
no_split_module_classes = model._no_split_modules
|
||||
)
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(checkpoint, **params)
|
||||
|
||||
# Hijack attention with xformers
|
||||
if any((shared.args.xformers, shared.args.sdp_attention)):
|
||||
llama_attn_hijack.hijack_llama_attention()
|
||||
|
||||
# Loading the tokenizer
|
||||
if any((k in shared.model_name.lower() for k in ['gpt4chan', 'gpt-4chan'])) and Path(f"{shared.args.model_dir}/gpt-j-6B/").exists():
|
||||
tokenizer = AutoTokenizer.from_pretrained(Path(f"{shared.args.model_dir}/gpt-j-6B/"))
|
||||
elif type(model) is transformers.LlamaForCausalLM:
|
||||
tokenizer = LlamaTokenizer.from_pretrained(Path(f"{shared.args.model_dir}/{shared.model_name}/"), clean_up_tokenization_spaces=True)
|
||||
# Leaving this here until the LLaMA tokenizer gets figured out.
|
||||
# For some people this fixes things, for others it causes an error.
|
||||
try:
|
||||
tokenizer.eos_token_id = 2
|
||||
tokenizer.bos_token_id = 1
|
||||
tokenizer.pad_token_id = 0
|
||||
except:
|
||||
pass
|
||||
else:
|
||||
tokenizer = AutoTokenizer.from_pretrained(Path(f"{shared.args.model_dir}/{shared.model_name}/"))
|
||||
tokenizer.truncation_side = 'left'
|
||||
@@ -194,23 +179,6 @@ def load_model(model_name):
|
||||
print(f"Loaded the model in {(time.time()-t0):.2f} seconds.")
|
||||
return model, tokenizer
|
||||
|
||||
|
||||
def clear_torch_cache():
|
||||
gc.collect()
|
||||
if not shared.args.cpu:
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def unload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
|
||||
|
||||
def reload_model():
|
||||
unload_model()
|
||||
shared.model, shared.tokenizer = load_model(shared.model_name)
|
||||
|
||||
|
||||
def load_soft_prompt(name):
|
||||
if name == 'None':
|
||||
shared.soft_prompt = False
|
||||
|
||||
@@ -35,7 +35,6 @@ settings = {
|
||||
'greeting': 'Hello there!',
|
||||
'end_of_turn': '',
|
||||
'stop_at_newline': False,
|
||||
'add_bos_token': True,
|
||||
'chat_prompt_size': 2048,
|
||||
'chat_prompt_size_min': 0,
|
||||
'chat_prompt_size_max': 2048,
|
||||
@@ -45,7 +44,7 @@ settings = {
|
||||
'default_extensions': [],
|
||||
'chat_default_extensions': ["gallery"],
|
||||
'presets': {
|
||||
'default': 'Default',
|
||||
'default': 'NovelAI-Sphinx Moth',
|
||||
'.*(alpaca|llama)': "LLaMA-Precise",
|
||||
'.*pygmalion': 'NovelAI-Storywriter',
|
||||
'.*RWKV': 'Naive',
|
||||
@@ -62,7 +61,6 @@ settings = {
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
def str2bool(v):
|
||||
if isinstance(v, bool):
|
||||
return v
|
||||
@@ -73,8 +71,7 @@ def str2bool(v):
|
||||
else:
|
||||
raise argparse.ArgumentTypeError('Boolean value expected.')
|
||||
|
||||
|
||||
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
|
||||
parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog,max_help_position=54))
|
||||
|
||||
# Basic settings
|
||||
parser.add_argument('--notebook', action='store_true', help='Launch the web UI in notebook mode, where the output is written to the same text box as the input.')
|
||||
@@ -90,7 +87,7 @@ parser.add_argument('--extensions', type=str, nargs="+", help='The list of exten
|
||||
parser.add_argument('--verbose', action='store_true', help='Print the prompts to the terminal.')
|
||||
|
||||
# Accelerate/transformers
|
||||
parser.add_argument('--cpu', action='store_true', help='Use the CPU to generate text. Warning: Training on CPU is extremely slow.')
|
||||
parser.add_argument('--cpu', action='store_true', help='Use the CPU to generate text.')
|
||||
parser.add_argument('--auto-devices', action='store_true', help='Automatically split the model across the available GPU(s) and CPU.')
|
||||
parser.add_argument('--gpu-memory', type=str, nargs="+", help='Maxmimum GPU memory in GiB to be allocated per GPU. Example: --gpu-memory 10 for a single GPU, --gpu-memory 10 5 for two GPUs. You can also set values in MiB like --gpu-memory 3500MiB.')
|
||||
parser.add_argument('--cpu-memory', type=str, help='Maximum CPU memory in GiB to allocate for offloaded weights. Same as above.')
|
||||
@@ -99,8 +96,6 @@ parser.add_argument('--disk-cache-dir', type=str, default="cache", help='Directo
|
||||
parser.add_argument('--load-in-8bit', action='store_true', help='Load the model with 8-bit precision.')
|
||||
parser.add_argument('--bf16', action='store_true', help='Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.')
|
||||
parser.add_argument('--no-cache', action='store_true', help='Set use_cache to False while generating text. This reduces the VRAM usage a bit at a performance cost.')
|
||||
parser.add_argument('--xformers', action='store_true', help="Use xformer's memory efficient attention. This should increase your tokens/s.")
|
||||
parser.add_argument('--sdp-attention', action='store_true', help="Use torch 2.0's sdp attention.")
|
||||
|
||||
# llama.cpp
|
||||
parser.add_argument('--threads', type=int, default=0, help='Number of threads to use in llama.cpp.')
|
||||
@@ -150,6 +145,5 @@ if args.cai_chat:
|
||||
print("Warning: --cai-chat is deprecated. Use --chat instead.")
|
||||
args.chat = True
|
||||
|
||||
|
||||
def is_chat():
|
||||
return args.chat
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
import random
|
||||
import gc
|
||||
import re
|
||||
import time
|
||||
import traceback
|
||||
@@ -12,33 +12,22 @@ from modules.callbacks import (Iteratorize, Stream,
|
||||
_SentinelTokenStoppingCriteria)
|
||||
from modules.extensions import apply_extensions
|
||||
from modules.html_generator import generate_4chan_html, generate_basic_html
|
||||
from modules.models import clear_torch_cache, local_rank
|
||||
from modules.models import local_rank
|
||||
|
||||
|
||||
def get_max_prompt_length(tokens):
|
||||
max_length = 2048 - tokens
|
||||
max_length = 2048-tokens
|
||||
if shared.soft_prompt:
|
||||
max_length -= shared.soft_prompt_tensor.shape[1]
|
||||
return max_length
|
||||
|
||||
|
||||
def encode(prompt, tokens_to_generate=0, add_special_tokens=True, add_bos_token=True):
|
||||
def encode(prompt, tokens_to_generate=0, add_special_tokens=True):
|
||||
if any((shared.is_RWKV, shared.is_llamacpp)):
|
||||
input_ids = shared.tokenizer.encode(str(prompt))
|
||||
input_ids = np.array(input_ids).reshape(1, len(input_ids))
|
||||
return input_ids
|
||||
else:
|
||||
input_ids = shared.tokenizer.encode(str(prompt), return_tensors='pt', truncation=True, max_length=get_max_prompt_length(tokens_to_generate), add_special_tokens=add_special_tokens)
|
||||
|
||||
# This is a hack for making replies more creative.
|
||||
if not add_bos_token and input_ids[0][0] == shared.tokenizer.bos_token_id:
|
||||
input_ids = input_ids[:, 1:]
|
||||
|
||||
# Llama adds this extra token when the first character is '\n', and this
|
||||
# compromises the stopping criteria, so we just remove it
|
||||
if type(shared.tokenizer) is transformers.LlamaTokenizer and input_ids[0][0] == 29871:
|
||||
input_ids = input_ids[:, 1:]
|
||||
|
||||
if shared.args.cpu:
|
||||
return input_ids
|
||||
elif shared.args.flexgen:
|
||||
@@ -51,7 +40,6 @@ def encode(prompt, tokens_to_generate=0, add_special_tokens=True, add_bos_token=
|
||||
else:
|
||||
return input_ids.cuda()
|
||||
|
||||
|
||||
def decode(output_ids):
|
||||
# Open Assistant relies on special tokens like <|endoftext|>
|
||||
if re.match('.*(oasst|galactica)-*', shared.model_name.lower()):
|
||||
@@ -61,12 +49,11 @@ def decode(output_ids):
|
||||
reply = reply.replace(r'<|endoftext|>', '')
|
||||
return reply
|
||||
|
||||
|
||||
def generate_softprompt_input_tensors(input_ids):
|
||||
inputs_embeds = shared.model.transformer.wte(input_ids)
|
||||
inputs_embeds = torch.cat((shared.soft_prompt_tensor, inputs_embeds), dim=1)
|
||||
filler_input_ids = torch.zeros((1, inputs_embeds.shape[1]), dtype=input_ids.dtype).to(shared.model.device)
|
||||
# filler_input_ids += shared.model.config.bos_token_id # setting dummy input_ids to bos tokens
|
||||
#filler_input_ids += shared.model.config.bos_token_id # setting dummy input_ids to bos tokens
|
||||
return inputs_embeds, filler_input_ids
|
||||
|
||||
# Removes empty replies from gpt4chan outputs
|
||||
@@ -88,7 +75,6 @@ def fix_galactica(s):
|
||||
s = re.sub(r"\n{3,}", "\n\n", s)
|
||||
return s
|
||||
|
||||
|
||||
def formatted_outputs(reply, model_name):
|
||||
if not shared.is_chat():
|
||||
if 'galactica' in model_name.lower():
|
||||
@@ -102,46 +88,45 @@ def formatted_outputs(reply, model_name):
|
||||
else:
|
||||
return reply
|
||||
|
||||
def clear_torch_cache():
|
||||
gc.collect()
|
||||
if not shared.args.cpu:
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
def set_manual_seed(seed):
|
||||
seed = int(seed)
|
||||
if seed == -1:
|
||||
seed = random.randint(1, 2**31)
|
||||
torch.manual_seed(seed)
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.manual_seed_all(seed)
|
||||
return seed
|
||||
|
||||
if seed != -1:
|
||||
torch.manual_seed(seed)
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.manual_seed_all(seed)
|
||||
|
||||
def stop_everything_event():
|
||||
shared.stop_everything = True
|
||||
|
||||
|
||||
def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]):
|
||||
clear_torch_cache()
|
||||
seed = set_manual_seed(generate_state['seed'])
|
||||
set_manual_seed(generate_state['seed'])
|
||||
shared.stop_everything = False
|
||||
generate_params = {}
|
||||
t0 = time.time()
|
||||
|
||||
original_question = question
|
||||
if not shared.is_chat():
|
||||
question = apply_extensions(question, 'input')
|
||||
question = apply_extensions(question, "input")
|
||||
if shared.args.verbose:
|
||||
print(f'\n\n{question}\n--------------------\n')
|
||||
print(f"\n\n{question}\n--------------------\n")
|
||||
|
||||
# These models are not part of Hugging Face, so we handle them
|
||||
# separately and terminate the function call earlier
|
||||
if any((shared.is_RWKV, shared.is_llamacpp)):
|
||||
for k in ['temperature', 'top_p', 'top_k', 'repetition_penalty']:
|
||||
generate_params[k] = generate_state[k]
|
||||
generate_params['token_count'] = generate_state['max_new_tokens']
|
||||
generate_params["token_count"] = generate_state["max_new_tokens"]
|
||||
try:
|
||||
if shared.args.no_stream:
|
||||
reply = shared.model.generate(context=question, **generate_params)
|
||||
output = original_question + reply
|
||||
output = original_question+reply
|
||||
if not shared.is_chat():
|
||||
reply = original_question + apply_extensions(reply, 'output')
|
||||
reply = original_question + apply_extensions(reply, "output")
|
||||
yield formatted_outputs(reply, shared.model_name)
|
||||
else:
|
||||
if not shared.is_chat():
|
||||
@@ -150,9 +135,9 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
# RWKV has proper streaming, which is very nice.
|
||||
# No need to generate 8 tokens at a time.
|
||||
for reply in shared.model.generate_with_streaming(context=question, **generate_params):
|
||||
output = original_question + reply
|
||||
output = original_question+reply
|
||||
if not shared.is_chat():
|
||||
reply = original_question + apply_extensions(reply, 'output')
|
||||
reply = original_question + apply_extensions(reply, "output")
|
||||
yield formatted_outputs(reply, shared.model_name)
|
||||
|
||||
except Exception:
|
||||
@@ -161,10 +146,10 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
t1 = time.time()
|
||||
original_tokens = len(encode(original_question)[0])
|
||||
new_tokens = len(encode(output)[0]) - original_tokens
|
||||
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens}, seed {seed})')
|
||||
print(f"Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens})")
|
||||
return
|
||||
|
||||
input_ids = encode(question, generate_state['max_new_tokens'], add_bos_token=generate_state['add_bos_token'])
|
||||
input_ids = encode(question, generate_state['max_new_tokens'])
|
||||
original_input_ids = input_ids
|
||||
output = input_ids[0]
|
||||
|
||||
@@ -177,28 +162,31 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
t = [encode(string, 0, add_special_tokens=False) for string in stopping_strings]
|
||||
stopping_criteria_list.append(_SentinelTokenStoppingCriteria(sentinel_token_ids=t, starting_idx=len(input_ids[0])))
|
||||
|
||||
generate_params["max_new_tokens"] = generate_state['max_new_tokens']
|
||||
if not shared.args.flexgen:
|
||||
for k in ['max_new_tokens', 'do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'encoder_repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping']:
|
||||
for k in ["do_sample", "temperature", "top_p", "typical_p", "repetition_penalty", "encoder_repetition_penalty", "top_k", "min_length", "no_repeat_ngram_size", "num_beams", "penalty_alpha", "length_penalty", "early_stopping"]:
|
||||
generate_params[k] = generate_state[k]
|
||||
generate_params['eos_token_id'] = eos_token_ids
|
||||
generate_params['stopping_criteria'] = stopping_criteria_list
|
||||
generate_params["eos_token_id"] = eos_token_ids
|
||||
generate_params["stopping_criteria"] = stopping_criteria_list
|
||||
if shared.args.no_stream:
|
||||
generate_params["min_length"] = 0
|
||||
else:
|
||||
for k in ['max_new_tokens', 'do_sample', 'temperature']:
|
||||
for k in ["do_sample", "temperature"]:
|
||||
generate_params[k] = generate_state[k]
|
||||
generate_params['stop'] = generate_state['eos_token_ids'][-1]
|
||||
generate_params["stop"] = generate_state["eos_token_ids"][-1]
|
||||
if not shared.args.no_stream:
|
||||
generate_params['max_new_tokens'] = 8
|
||||
generate_params["max_new_tokens"] = 8
|
||||
|
||||
if shared.args.no_cache:
|
||||
generate_params.update({'use_cache': False})
|
||||
generate_params.update({"use_cache": False})
|
||||
if shared.args.deepspeed:
|
||||
generate_params.update({'synced_gpus': True})
|
||||
generate_params.update({"synced_gpus": True})
|
||||
if shared.soft_prompt:
|
||||
inputs_embeds, filler_input_ids = generate_softprompt_input_tensors(input_ids)
|
||||
generate_params.update({'inputs_embeds': inputs_embeds})
|
||||
generate_params.update({'inputs': filler_input_ids})
|
||||
generate_params.update({"inputs_embeds": inputs_embeds})
|
||||
generate_params.update({"inputs": filler_input_ids})
|
||||
else:
|
||||
generate_params.update({'inputs': input_ids})
|
||||
generate_params.update({"inputs": input_ids})
|
||||
|
||||
try:
|
||||
# Generate the entire reply at once.
|
||||
@@ -213,7 +201,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
new_tokens = len(output) - len(input_ids[0])
|
||||
reply = decode(output[-new_tokens:])
|
||||
if not shared.is_chat():
|
||||
reply = original_question + apply_extensions(reply, 'output')
|
||||
reply = original_question + apply_extensions(reply, "output")
|
||||
|
||||
yield formatted_outputs(reply, shared.model_name)
|
||||
|
||||
@@ -240,7 +228,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
new_tokens = len(output) - len(input_ids[0])
|
||||
reply = decode(output[-new_tokens:])
|
||||
if not shared.is_chat():
|
||||
reply = original_question + apply_extensions(reply, 'output')
|
||||
reply = original_question + apply_extensions(reply, "output")
|
||||
|
||||
if output[-1] in eos_token_ids:
|
||||
break
|
||||
@@ -248,7 +236,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
|
||||
# Stream the output naively for FlexGen since it doesn't support 'stopping_criteria'
|
||||
else:
|
||||
for i in range(generate_state['max_new_tokens'] // 8 + 1):
|
||||
for i in range(generate_state['max_new_tokens']//8+1):
|
||||
clear_torch_cache()
|
||||
with torch.no_grad():
|
||||
output = shared.model.generate(**generate_params)[0]
|
||||
@@ -258,7 +246,7 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
new_tokens = len(output) - len(original_input_ids[0])
|
||||
reply = decode(output[-new_tokens:])
|
||||
if not shared.is_chat():
|
||||
reply = original_question + apply_extensions(reply, 'output')
|
||||
reply = original_question + apply_extensions(reply, "output")
|
||||
|
||||
if np.count_nonzero(np.isin(input_ids[0], eos_token_ids)) < np.count_nonzero(np.isin(output, eos_token_ids)):
|
||||
break
|
||||
@@ -267,10 +255,10 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
input_ids = np.reshape(output, (1, output.shape[0]))
|
||||
if shared.soft_prompt:
|
||||
inputs_embeds, filler_input_ids = generate_softprompt_input_tensors(input_ids)
|
||||
generate_params.update({'inputs_embeds': inputs_embeds})
|
||||
generate_params.update({'inputs': filler_input_ids})
|
||||
generate_params.update({"inputs_embeds": inputs_embeds})
|
||||
generate_params.update({"inputs": filler_input_ids})
|
||||
else:
|
||||
generate_params.update({'inputs': input_ids})
|
||||
generate_params.update({"inputs": input_ids})
|
||||
|
||||
yield formatted_outputs(reply, shared.model_name)
|
||||
|
||||
@@ -279,6 +267,6 @@ def generate_reply(question, generate_state, eos_token=None, stopping_strings=[]
|
||||
finally:
|
||||
t1 = time.time()
|
||||
original_tokens = len(original_input_ids[0])
|
||||
new_tokens = len(output) - original_tokens
|
||||
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens}, seed {seed})')
|
||||
new_tokens = len(output)-original_tokens
|
||||
print(f"Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens})")
|
||||
return
|
||||
|
||||
@@ -19,10 +19,8 @@ CURRENT_STEPS = 0
|
||||
MAX_STEPS = 0
|
||||
CURRENT_GRADIENT_ACCUM = 1
|
||||
|
||||
|
||||
def get_dataset(path: str, ext: str):
|
||||
return ['None'] + sorted(set([k.stem for k in Path(path).glob(f'*.{ext}') if k.stem != 'put-trainer-datasets-here']), key=str.lower)
|
||||
|
||||
return ['None'] + sorted(set((k.stem for k in Path(path).glob(f'*.{ext}'))), key=str.lower)
|
||||
|
||||
def create_train_interface():
|
||||
with gr.Tab('Train LoRA', elem_id='lora-train-tab'):
|
||||
@@ -46,35 +44,29 @@ def create_train_interface():
|
||||
with gr.Tab(label="Formatted Dataset"):
|
||||
with gr.Row():
|
||||
dataset = gr.Dropdown(choices=get_dataset('training/datasets', 'json'), value='None', label='Dataset', info='The dataset file to use for training.')
|
||||
ui.create_refresh_button(dataset, lambda: None, lambda: {'choices': get_dataset('training/datasets', 'json')}, 'refresh-button')
|
||||
eval_dataset = gr.Dropdown(choices=get_dataset('training/datasets', 'json'), value='None', label='Evaluation Dataset', info='The (optional) dataset file used to evaluate the model after training.')
|
||||
ui.create_refresh_button(eval_dataset, lambda: None, lambda: {'choices': get_dataset('training/datasets', 'json')}, 'refresh-button')
|
||||
ui.create_refresh_button(dataset, lambda : None, lambda : {'choices': get_dataset('training/datasets', 'json')}, 'refresh-button')
|
||||
eval_dataset = gr.Dropdown(choices=get_dataset('training/datasets', 'json'), value='None', label='Evaluation Dataset', info='The dataset file used to evaluate the model after training.')
|
||||
ui.create_refresh_button(eval_dataset, lambda : None, lambda : {'choices': get_dataset('training/datasets', 'json')}, 'refresh-button')
|
||||
format = gr.Dropdown(choices=get_dataset('training/formats', 'json'), value='None', label='Data Format', info='The format file used to decide how to format the dataset input.')
|
||||
ui.create_refresh_button(format, lambda: None, lambda: {'choices': get_dataset('training/formats', 'json')}, 'refresh-button')
|
||||
|
||||
ui.create_refresh_button(format, lambda : None, lambda : {'choices': get_dataset('training/formats', 'json')}, 'refresh-button')
|
||||
with gr.Tab(label="Raw Text File"):
|
||||
with gr.Row():
|
||||
raw_text_file = gr.Dropdown(choices=get_dataset('training/datasets', 'txt'), value='None', label='Text File', info='The raw text file to use for training.')
|
||||
ui.create_refresh_button(raw_text_file, lambda: None, lambda: {'choices': get_dataset('training/datasets', 'txt')}, 'refresh-button')
|
||||
with gr.Row():
|
||||
overlap_len = gr.Slider(label='Overlap Length', minimum=0, maximum=512, value=128, step=16, info='Overlap length - ie how many tokens from the prior chunk of text to include into the next chunk. (The chunks themselves will be of a size determined by Cutoff Length below). Setting overlap to exactly half the cutoff length may be ideal.')
|
||||
newline_favor_len = gr.Slider(label='Prefer Newline Cut Length', minimum=0, maximum=512, value=128, step=16, info='Length (in characters, not tokens) of the maximum distance to shift an overlap cut by to ensure chunks cut at newlines. If too low, cuts may occur in the middle of lines.')
|
||||
ui.create_refresh_button(raw_text_file, lambda : None, lambda : {'choices': get_dataset('training/datasets', 'txt')}, 'refresh-button')
|
||||
overlap_len = gr.Slider(label='Overlap Length', minimum=0,maximum=512, value=128, step=16, info='Overlap length - ie how many tokens from the prior chunk of text to include into the next chunk. (The chunks themselves will be of a size determined by Cutoff Length above). Setting overlap to exactly half the cutoff length may be ideal.')
|
||||
|
||||
with gr.Row():
|
||||
start_button = gr.Button("Start LoRA Training")
|
||||
stop_button = gr.Button("Interrupt")
|
||||
|
||||
output = gr.Markdown(value="Ready")
|
||||
start_button.click(do_train, [lora_name, micro_batch_size, batch_size, epochs, learning_rate, lora_rank, lora_alpha, lora_dropout,
|
||||
cutoff_len, dataset, eval_dataset, format, raw_text_file, overlap_len, newline_favor_len], [output])
|
||||
start_button.click(do_train, [lora_name, micro_batch_size, batch_size, epochs, learning_rate, lora_rank, lora_alpha, lora_dropout, cutoff_len, dataset, eval_dataset, format, raw_text_file, overlap_len], [output])
|
||||
stop_button.click(do_interrupt, [], [], cancels=[], queue=False)
|
||||
|
||||
|
||||
def do_interrupt():
|
||||
global WANT_INTERRUPT
|
||||
WANT_INTERRUPT = True
|
||||
|
||||
|
||||
class Callbacks(transformers.TrainerCallback):
|
||||
def on_step_begin(self, args: transformers.TrainingArguments, state: transformers.TrainerState, control: transformers.TrainerControl, **kwargs):
|
||||
global CURRENT_STEPS, MAX_STEPS
|
||||
@@ -83,7 +75,6 @@ class Callbacks(transformers.TrainerCallback):
|
||||
if WANT_INTERRUPT:
|
||||
control.should_epoch_stop = True
|
||||
control.should_training_stop = True
|
||||
|
||||
def on_substep_end(self, args: transformers.TrainingArguments, state: transformers.TrainerState, control: transformers.TrainerControl, **kwargs):
|
||||
global CURRENT_STEPS
|
||||
CURRENT_STEPS += 1
|
||||
@@ -91,7 +82,6 @@ class Callbacks(transformers.TrainerCallback):
|
||||
control.should_epoch_stop = True
|
||||
control.should_training_stop = True
|
||||
|
||||
|
||||
def clean_path(base_path: str, path: str):
|
||||
""""Strips unusual symbols and forcibly builds a path as relative to the intended directory."""
|
||||
# TODO: Probably could do with a security audit to guarantee there's no ways this can be bypassed to target an unwanted path.
|
||||
@@ -101,9 +91,8 @@ def clean_path(base_path: str, path: str):
|
||||
return path
|
||||
return f'{Path(base_path).absolute()}/{path}'
|
||||
|
||||
|
||||
def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int, learning_rate: str, lora_rank: int, lora_alpha: int, lora_dropout: float,
|
||||
cutoff_len: int, dataset: str, eval_dataset: str, format: str, raw_text_file: str, overlap_len: int, newline_favor_len: int):
|
||||
def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int, learning_rate: str, lora_rank: int,
|
||||
lora_alpha: int, lora_dropout: float, cutoff_len: int, dataset: str, eval_dataset: str, format: str, raw_text_file: str, overlap_len: int):
|
||||
global WANT_INTERRUPT, CURRENT_STEPS, MAX_STEPS, CURRENT_GRADIENT_ACCUM
|
||||
WANT_INTERRUPT = False
|
||||
CURRENT_STEPS = 0
|
||||
@@ -114,25 +103,6 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
lora_name = f"{shared.args.lora_dir}/{clean_path(None, lora_name)}"
|
||||
actual_lr = float(learning_rate)
|
||||
|
||||
model_type = type(shared.model).__name__
|
||||
if model_type != "LlamaForCausalLM":
|
||||
if model_type == "PeftModelForCausalLM":
|
||||
yield "You are trying to train a LoRA while you already have another LoRA loaded. This will work, but may have unexpected effects. *(Will continue anyway in 5 seconds, press `Interrupt` to stop.)*"
|
||||
print("Warning: Training LoRA over top of another LoRA. May have unexpected effects.")
|
||||
else:
|
||||
yield "LoRA training has only currently been validated for LLaMA models. Unexpected errors may follow. *(Will continue anyway in 5 seconds, press `Interrupt` to stop.)*"
|
||||
print(f"Warning: LoRA training has only currently been validated for LLaMA models. (Found model type: {model_type})")
|
||||
time.sleep(5)
|
||||
|
||||
if shared.args.wbits > 0 or shared.args.gptq_bits > 0:
|
||||
yield "LoRA training does not yet support 4bit. Please use `--load-in-8bit` for now."
|
||||
return
|
||||
|
||||
elif not shared.args.load_in_8bit:
|
||||
yield "It is highly recommended you use `--load-in-8bit` for LoRA training. *(Will continue anyway in 2 seconds, press `Interrupt` to stop.)*"
|
||||
print("Warning: It is highly recommended you use `--load-in-8bit` for LoRA training.")
|
||||
time.sleep(2) # Give it a moment for the message to show in UI before continuing
|
||||
|
||||
if cutoff_len <= 0 or micro_batch_size <= 0 or batch_size <= 0 or actual_lr <= 0 or lora_rank <= 0 or lora_alpha <= 0:
|
||||
yield "Cannot input zeroes."
|
||||
return
|
||||
@@ -152,24 +122,19 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
# == Prep the dataset, format, etc ==
|
||||
if raw_text_file not in ['None', '']:
|
||||
print("Loading raw text file dataset...")
|
||||
with open(clean_path('training/datasets', f'{raw_text_file}.txt'), 'r', encoding='utf-8') as file:
|
||||
with open(clean_path('training/datasets', f'{raw_text_file}.txt'), 'r') as file:
|
||||
raw_text = file.read()
|
||||
tokens = shared.tokenizer.encode(raw_text)
|
||||
del raw_text # Note: could be a gig for a large dataset, so delete redundant data as we go to be safe on RAM
|
||||
|
||||
del raw_text # Note: could be a gig for a large dataset, so delete redundant data as we go to be safe on RAM
|
||||
tokens = list(split_chunks(tokens, cutoff_len - overlap_len))
|
||||
for i in range(1, len(tokens)):
|
||||
tokens[i] = tokens[i - 1][-overlap_len:] + tokens[i]
|
||||
text_chunks = [shared.tokenizer.decode(x) for x in tokens]
|
||||
del tokens
|
||||
|
||||
if newline_favor_len > 0:
|
||||
text_chunks = [cut_chunk_for_newline(x, newline_favor_len) for x in text_chunks]
|
||||
|
||||
train_data = Dataset.from_list([tokenize(x) for x in text_chunks])
|
||||
del text_chunks
|
||||
train_data = train_data.shuffle()
|
||||
data = Dataset.from_list([tokenize(x) for x in text_chunks])
|
||||
train_data = data.shuffle()
|
||||
eval_data = None
|
||||
del text_chunks
|
||||
|
||||
else:
|
||||
if dataset in ['None', '']:
|
||||
@@ -204,18 +169,18 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
else:
|
||||
eval_data = load_dataset("json", data_files=clean_path('training/datasets', f'{eval_dataset}.json'))
|
||||
eval_data = eval_data['train'].shuffle().map(generate_and_tokenize_prompt)
|
||||
|
||||
|
||||
# == Start prepping the model itself ==
|
||||
if not hasattr(shared.model, 'lm_head') or hasattr(shared.model.lm_head, 'weight'):
|
||||
print("Getting model ready...")
|
||||
prepare_model_for_int8_training(shared.model)
|
||||
|
||||
|
||||
print("Prepping for training...")
|
||||
config = LoraConfig(
|
||||
r=lora_rank,
|
||||
lora_alpha=lora_alpha,
|
||||
# TODO: Should target_modules be configurable?
|
||||
target_modules=["q_proj", "v_proj"],
|
||||
target_modules=[ "q_proj", "v_proj" ],
|
||||
lora_dropout=lora_dropout,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM"
|
||||
@@ -238,7 +203,7 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
warmup_steps=100,
|
||||
num_train_epochs=epochs,
|
||||
learning_rate=actual_lr,
|
||||
fp16=False if shared.args.cpu else True,
|
||||
fp16=True,
|
||||
logging_steps=20,
|
||||
evaluation_strategy="steps" if eval_data is not None else "no",
|
||||
save_strategy="steps",
|
||||
@@ -248,8 +213,7 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
save_total_limit=3,
|
||||
load_best_model_at_end=True if eval_data is not None else False,
|
||||
# TODO: Enable multi-device support
|
||||
ddp_find_unused_parameters=None,
|
||||
no_cuda=shared.args.cpu
|
||||
ddp_find_unused_parameters=None
|
||||
),
|
||||
data_collator=transformers.DataCollatorForLanguageModeling(shared.tokenizer, mlm=False),
|
||||
callbacks=list([Callbacks()])
|
||||
@@ -268,37 +232,33 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
# TODO: save/load checkpoints to resume from?
|
||||
print("Starting training...")
|
||||
yield "Starting..."
|
||||
if WANT_INTERRUPT:
|
||||
yield "Interrupted before start."
|
||||
return
|
||||
|
||||
def threaded_run():
|
||||
def threadedRun():
|
||||
trainer.train()
|
||||
|
||||
thread = threading.Thread(target=threaded_run)
|
||||
thread = threading.Thread(target=threadedRun)
|
||||
thread.start()
|
||||
last_step = 0
|
||||
start_time = time.perf_counter()
|
||||
lastStep = 0
|
||||
startTime = time.perf_counter()
|
||||
|
||||
while thread.is_alive():
|
||||
time.sleep(0.5)
|
||||
if WANT_INTERRUPT:
|
||||
yield "Interrupting, please wait... *(Run will stop after the current training step completes.)*"
|
||||
|
||||
elif CURRENT_STEPS != last_step:
|
||||
last_step = CURRENT_STEPS
|
||||
time_elapsed = time.perf_counter() - start_time
|
||||
if time_elapsed <= 0:
|
||||
timer_info = ""
|
||||
total_time_estimate = 999
|
||||
elif CURRENT_STEPS != lastStep:
|
||||
lastStep = CURRENT_STEPS
|
||||
timeElapsed = time.perf_counter() - startTime
|
||||
if timeElapsed <= 0:
|
||||
timerInfo = ""
|
||||
totalTimeEstimate = 999
|
||||
else:
|
||||
its = CURRENT_STEPS / time_elapsed
|
||||
its = CURRENT_STEPS / timeElapsed
|
||||
if its > 1:
|
||||
timer_info = f"`{its:.2f}` it/s"
|
||||
timerInfo = f"`{its:.2f}` it/s"
|
||||
else:
|
||||
timer_info = f"`{1.0/its:.2f}` s/it"
|
||||
total_time_estimate = (1.0 / its) * (MAX_STEPS)
|
||||
yield f"Running... **{CURRENT_STEPS}** / **{MAX_STEPS}** ... {timer_info}, {format_time(time_elapsed)} / {format_time(total_time_estimate)} ... {format_time(total_time_estimate - time_elapsed)} remaining"
|
||||
timerInfo = f"`{1.0/its:.2f}` s/it"
|
||||
totalTimeEstimate = (1.0/its) * (MAX_STEPS)
|
||||
yield f"Running... **{CURRENT_STEPS}** / **{MAX_STEPS}** ... {timerInfo}, `{timeElapsed:.0f}`/`{totalTimeEstimate:.0f}` seconds"
|
||||
|
||||
print("Training complete, saving...")
|
||||
lora_model.save_pretrained(lora_name)
|
||||
@@ -310,31 +270,6 @@ def do_train(lora_name: str, micro_batch_size: int, batch_size: int, epochs: int
|
||||
print("Training complete!")
|
||||
yield f"Done! LoRA saved to `{lora_name}`"
|
||||
|
||||
|
||||
def split_chunks(arr, step):
|
||||
for i in range(0, len(arr), step):
|
||||
yield arr[i:i + step]
|
||||
|
||||
|
||||
def cut_chunk_for_newline(chunk: str, max_length: int):
|
||||
if '\n' not in chunk:
|
||||
return chunk
|
||||
first_newline = chunk.index('\n')
|
||||
if first_newline < max_length:
|
||||
chunk = chunk[first_newline + 1:]
|
||||
if '\n' not in chunk:
|
||||
return chunk
|
||||
last_newline = chunk.rindex('\n')
|
||||
if len(chunk) - last_newline < max_length:
|
||||
chunk = chunk[:last_newline]
|
||||
return chunk
|
||||
|
||||
|
||||
def format_time(seconds: float):
|
||||
if seconds < 120:
|
||||
return f"`{seconds:.0f}` seconds"
|
||||
minutes = seconds / 60
|
||||
if minutes < 120:
|
||||
return f"`{minutes:.0f}` minutes"
|
||||
hours = minutes / 60
|
||||
return f"`{hours:.0f}` hours"
|
||||
|
||||
@@ -13,7 +13,6 @@ with open(Path(__file__).resolve().parent / '../css/main.js', 'r') as f:
|
||||
with open(Path(__file__).resolve().parent / '../css/chat.js', 'r') as f:
|
||||
chat_js = f.read()
|
||||
|
||||
|
||||
class ToolButton(gr.Button, gr.components.FormComponent):
|
||||
"""Small button with single emoji as text, fits inside gradio forms"""
|
||||
|
||||
@@ -23,7 +22,6 @@ class ToolButton(gr.Button, gr.components.FormComponent):
|
||||
def get_block_name(self):
|
||||
return "button"
|
||||
|
||||
|
||||
def create_refresh_button(refresh_component, refresh_method, refreshed_args, elem_id):
|
||||
def refresh():
|
||||
refresh_method()
|
||||
|
||||
@@ -1,18 +1,16 @@
|
||||
accelerate==0.18.0
|
||||
bitsandbytes==0.37.2
|
||||
datasets
|
||||
flexgen==0.1.7
|
||||
gradio==3.24.1
|
||||
llamacpp==0.1.11
|
||||
markdown
|
||||
numpy
|
||||
Pillow>=9.5.0
|
||||
peft==0.2.0
|
||||
requests
|
||||
rwkv==0.7.3
|
||||
rwkv==0.7.2
|
||||
safetensors==0.3.0
|
||||
sentencepiece
|
||||
pyyaml
|
||||
tqdm
|
||||
git+https://github.com/huggingface/transformers
|
||||
bitsandbytes==0.37.2; platform_system != "Windows"
|
||||
llama-cpp-python==0.1.32; platform_system != "Windows"
|
||||
https://github.com/abetlen/llama-cpp-python/releases/download/v0.1.30/llama_cpp_python-0.1.30-cp310-cp310-win_amd64.whl; platform_system == "Windows"
|
||||
git+https://github.com/huggingface/transformers@9eae4aa57650c1dbe1becd4e0979f6ad1e572ac0
|
||||
|
||||
270
server.py
270
server.py
@@ -2,14 +2,11 @@ import os
|
||||
|
||||
os.environ['GRADIO_ANALYTICS_ENABLED'] = 'False'
|
||||
|
||||
import importlib
|
||||
import io
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import traceback
|
||||
import zipfile
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
@@ -18,12 +15,12 @@ import gradio as gr
|
||||
from PIL import Image
|
||||
|
||||
import modules.extensions as extensions_module
|
||||
from modules import api, chat, shared, training, ui
|
||||
from modules import chat, shared, training, ui, api
|
||||
from modules.html_generator import chat_html_wrapper
|
||||
from modules.LoRA import add_lora_to_model
|
||||
from modules.models import load_model, load_soft_prompt, unload_model
|
||||
from modules.text_generation import generate_reply, stop_everything_event
|
||||
|
||||
from modules.models import load_model, load_soft_prompt
|
||||
from modules.text_generation import (clear_torch_cache, generate_reply,
|
||||
stop_everything_event)
|
||||
|
||||
# Loading custom settings
|
||||
settings_file = None
|
||||
@@ -37,18 +34,15 @@ if settings_file is not None:
|
||||
for item in new_settings:
|
||||
shared.settings[item] = new_settings[item]
|
||||
|
||||
|
||||
def get_available_models():
|
||||
if shared.args.flexgen:
|
||||
return sorted([re.sub('-np$', '', item.name) for item in list(Path(f'{shared.args.model_dir}/').glob('*')) if item.name.endswith('-np')], key=str.lower)
|
||||
else:
|
||||
return sorted([re.sub('.pth$', '', item.name) for item in list(Path(f'{shared.args.model_dir}/').glob('*')) if not item.name.endswith(('.txt', '-np', '.pt', '.json'))], key=str.lower)
|
||||
|
||||
|
||||
def get_available_presets():
|
||||
return sorted(set((k.stem for k in Path('presets').glob('*.txt'))), key=str.lower)
|
||||
|
||||
|
||||
def get_available_prompts():
|
||||
prompts = []
|
||||
prompts += sorted(set((k.stem for k in Path('prompts').glob('[0-9]*.txt'))), key=str.lower, reverse=True)
|
||||
@@ -56,31 +50,26 @@ def get_available_prompts():
|
||||
prompts += ['None']
|
||||
return prompts
|
||||
|
||||
|
||||
def get_available_characters():
|
||||
paths = (x for x in Path('characters').iterdir() if x.suffix in ('.json', '.yaml', '.yml'))
|
||||
return ['None'] + sorted(set((k.stem for k in paths if k.stem != "instruction-following")), key=str.lower)
|
||||
|
||||
|
||||
def get_available_instruction_templates():
|
||||
path = "characters/instruction-following"
|
||||
paths = []
|
||||
if os.path.exists(path):
|
||||
paths = (x for x in Path(path).iterdir() if x.suffix in ('.json', '.yaml', '.yml'))
|
||||
paths = (x for x in Path('characters/instruction-following').iterdir() if x.suffix in ('.json', '.yaml', '.yml'))
|
||||
return ['None'] + sorted(set((k.stem for k in paths)), key=str.lower)
|
||||
|
||||
|
||||
def get_available_extensions():
|
||||
return sorted(set(map(lambda x: x.parts[1], Path('extensions').glob('*/script.py'))), key=str.lower)
|
||||
|
||||
return sorted(set(map(lambda x : x.parts[1], Path('extensions').glob('*/script.py'))), key=str.lower)
|
||||
|
||||
def get_available_softprompts():
|
||||
return ['None'] + sorted(set((k.stem for k in Path('softprompts').glob('*.zip'))), key=str.lower)
|
||||
|
||||
|
||||
def get_available_loras():
|
||||
return ['None'] + sorted([item.name for item in list(Path(shared.args.lora_dir).glob('*')) if not item.name.endswith(('.txt', '-np', '.pt', '.json'))], key=str.lower)
|
||||
|
||||
def unload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
|
||||
def load_model_wrapper(selected_model):
|
||||
if selected_model != shared.model_name:
|
||||
@@ -92,12 +81,10 @@ def load_model_wrapper(selected_model):
|
||||
|
||||
return selected_model
|
||||
|
||||
|
||||
def load_lora_wrapper(selected_lora):
|
||||
add_lora_to_model(selected_lora)
|
||||
return selected_lora
|
||||
|
||||
|
||||
def load_preset_values(preset_menu, state, return_dict=False):
|
||||
generate_params = {
|
||||
'do_sample': True,
|
||||
@@ -128,7 +115,6 @@ def load_preset_values(preset_menu, state, return_dict=False):
|
||||
state.update(generate_params)
|
||||
return state, *[generate_params[k] for k in ['do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'encoder_repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping']]
|
||||
|
||||
|
||||
def upload_soft_prompt(file):
|
||||
with zipfile.ZipFile(io.BytesIO(file)) as zf:
|
||||
zf.extract('meta.json')
|
||||
@@ -141,6 +127,16 @@ def upload_soft_prompt(file):
|
||||
|
||||
return name
|
||||
|
||||
def create_model_and_preset_menus():
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
shared.gradio['model_menu'] = gr.Dropdown(choices=available_models, value=shared.model_name, label='Model')
|
||||
ui.create_refresh_button(shared.gradio['model_menu'], lambda : None, lambda : {'choices': get_available_models()}, 'refresh-button')
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
shared.gradio['preset_menu'] = gr.Dropdown(choices=available_presets, value=default_preset if not shared.args.flexgen else 'Naive', label='Generation parameters preset')
|
||||
ui.create_refresh_button(shared.gradio['preset_menu'], lambda : None, lambda : {'choices': get_available_presets()}, 'refresh-button')
|
||||
|
||||
def save_prompt(text):
|
||||
fname = f"{datetime.now().strftime('%Y-%m-%d-%H%M%S')}.txt"
|
||||
@@ -148,7 +144,6 @@ def save_prompt(text):
|
||||
f.write(text)
|
||||
return f"Saved to prompts/{fname}"
|
||||
|
||||
|
||||
def load_prompt(fname):
|
||||
if fname in ['None', '']:
|
||||
return ''
|
||||
@@ -159,13 +154,12 @@ def load_prompt(fname):
|
||||
text = text[:-1]
|
||||
return text
|
||||
|
||||
|
||||
def create_prompt_menus():
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
shared.gradio['prompt_menu'] = gr.Dropdown(choices=get_available_prompts(), value='None', label='Prompt')
|
||||
ui.create_refresh_button(shared.gradio['prompt_menu'], lambda: None, lambda: {'choices': get_available_prompts()}, 'refresh-button')
|
||||
ui.create_refresh_button(shared.gradio['prompt_menu'], lambda : None, lambda : {'choices': get_available_prompts()}, 'refresh-button')
|
||||
|
||||
with gr.Column():
|
||||
with gr.Column():
|
||||
@@ -175,96 +169,39 @@ def create_prompt_menus():
|
||||
shared.gradio['prompt_menu'].change(load_prompt, [shared.gradio['prompt_menu']], [shared.gradio['textbox']], show_progress=False)
|
||||
shared.gradio['save_prompt'].click(save_prompt, [shared.gradio['textbox']], [shared.gradio['status']], show_progress=False)
|
||||
|
||||
|
||||
def download_model_wrapper(repo_id):
|
||||
try:
|
||||
downloader = importlib.import_module("download-model")
|
||||
|
||||
model = repo_id
|
||||
branch = "main"
|
||||
check = False
|
||||
|
||||
yield("Cleaning up the model/branch names")
|
||||
model, branch = downloader.sanitize_model_and_branch_names(model, branch)
|
||||
|
||||
yield("Getting the download links from Hugging Face")
|
||||
links, sha256, is_lora = downloader.get_download_links_from_huggingface(model, branch, text_only=False)
|
||||
|
||||
yield("Getting the output folder")
|
||||
output_folder = downloader.get_output_folder(model, branch, is_lora)
|
||||
|
||||
if check:
|
||||
yield("Checking previously downloaded files")
|
||||
downloader.check_model_files(model, branch, links, sha256, output_folder)
|
||||
else:
|
||||
yield(f"Downloading files to {output_folder}")
|
||||
downloader.download_model_files(model, branch, links, sha256, output_folder, threads=1)
|
||||
yield("Done!")
|
||||
except:
|
||||
yield traceback.format_exc()
|
||||
|
||||
|
||||
def create_model_menus():
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
shared.gradio['model_menu'] = gr.Dropdown(choices=available_models, value=shared.model_name, label='Model')
|
||||
ui.create_refresh_button(shared.gradio['model_menu'], lambda: None, lambda: {'choices': get_available_models()}, 'refresh-button')
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
shared.gradio['lora_menu'] = gr.Dropdown(choices=available_loras, value=shared.lora_name, label='LoRA')
|
||||
ui.create_refresh_button(shared.gradio['lora_menu'], lambda: None, lambda: {'choices': get_available_loras()}, 'refresh-button')
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
shared.gradio['custom_model_menu'] = gr.Textbox(label="Download custom model or LoRA",
|
||||
info="Enter Hugging Face username/model path, e.g: facebook/galactica-125m")
|
||||
with gr.Column():
|
||||
shared.gradio['download_button'] = gr.Button("Download")
|
||||
shared.gradio['download_status'] = gr.Markdown()
|
||||
with gr.Column():
|
||||
pass
|
||||
|
||||
shared.gradio['model_menu'].change(load_model_wrapper, shared.gradio['model_menu'], shared.gradio['model_menu'], show_progress=True)
|
||||
shared.gradio['lora_menu'].change(load_lora_wrapper, shared.gradio['lora_menu'], shared.gradio['lora_menu'], show_progress=True)
|
||||
shared.gradio['download_button'].click(download_model_wrapper, shared.gradio['custom_model_menu'], shared.gradio['download_status'], show_progress=False)
|
||||
|
||||
|
||||
def create_settings_menus(default_preset):
|
||||
generate_params = load_preset_values(default_preset if not shared.args.flexgen else 'Naive', {}, return_dict=True)
|
||||
for k in ['max_new_tokens', 'seed', 'stop_at_newline', 'chat_prompt_size', 'chat_generation_attempts', 'add_bos_token']:
|
||||
for k in ['max_new_tokens', 'seed', 'stop_at_newline', 'chat_prompt_size', 'chat_generation_attempts']:
|
||||
generate_params[k] = shared.settings[k]
|
||||
shared.gradio['generate_state'] = gr.State(generate_params)
|
||||
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
with gr.Row():
|
||||
shared.gradio['preset_menu'] = gr.Dropdown(choices=available_presets, value=default_preset if not shared.args.flexgen else 'Naive', label='Generation parameters preset')
|
||||
ui.create_refresh_button(shared.gradio['preset_menu'], lambda: None, lambda: {'choices': get_available_presets()}, 'refresh-button')
|
||||
create_model_and_preset_menus()
|
||||
with gr.Column():
|
||||
shared.gradio['seed'] = gr.Number(value=shared.settings['seed'], label='Seed (-1 for random)')
|
||||
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
with gr.Box():
|
||||
gr.Markdown('Custom generation parameters ([click here to view technical documentation](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig))')
|
||||
gr.Markdown('Custom generation parameters ([reference](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig))')
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
shared.gradio['temperature'] = gr.Slider(0.01, 1.99, value=generate_params['temperature'], step=0.01, label='temperature', info='Primary factor to control randomness of outputs. 0 = deterministic (only the most likely token is used). Higher value = more randomness.')
|
||||
shared.gradio['top_p'] = gr.Slider(0.0, 1.0, value=generate_params['top_p'], step=0.01, label='top_p', info='If not set to 1, select tokens with probabilities adding up to less than this number. Higher value = higher range of possible random results.')
|
||||
shared.gradio['top_k'] = gr.Slider(0, 200, value=generate_params['top_k'], step=1, label='top_k', info='Similar to top_p, but select instead only the top_k most likely tokens. Higher value = higher range of possible random results.')
|
||||
shared.gradio['typical_p'] = gr.Slider(0.0, 1.0, value=generate_params['typical_p'], step=0.01, label='typical_p', info='If not set to 1, select only tokens that are at least this much more likely to appear than random tokens, given the prior text.')
|
||||
shared.gradio['temperature'] = gr.Slider(0.01, 1.99, value=generate_params['temperature'], step=0.01, label='temperature')
|
||||
shared.gradio['top_p'] = gr.Slider(0.0,1.0,value=generate_params['top_p'],step=0.01,label='top_p')
|
||||
shared.gradio['top_k'] = gr.Slider(0,200,value=generate_params['top_k'],step=1,label='top_k')
|
||||
shared.gradio['typical_p'] = gr.Slider(0.0,1.0,value=generate_params['typical_p'],step=0.01,label='typical_p')
|
||||
with gr.Column():
|
||||
shared.gradio['repetition_penalty'] = gr.Slider(1.0, 1.5, value=generate_params['repetition_penalty'], step=0.01, label='repetition_penalty', info='Exponential penalty factor for repeating prior tokens. 1 means no penalty, higher value = less repetition, lower value = more repetition.')
|
||||
shared.gradio['encoder_repetition_penalty'] = gr.Slider(0.8, 1.5, value=generate_params['encoder_repetition_penalty'], step=0.01, label='encoder_repetition_penalty', info='Also known as the "Hallucinations filter". Used to penalize tokens that are *not* in the prior text. Higher value = more likely to stay in context, lower value = more likely to diverge.')
|
||||
shared.gradio['no_repeat_ngram_size'] = gr.Slider(0, 20, step=1, value=generate_params['no_repeat_ngram_size'], label='no_repeat_ngram_size', info='If not set to 0, specifies the length of token sets that are completely blocked from repeating at all. Higher values = blocks larger phrases, lower values = blocks words or letters from repeating. Only 0 or high values are a good idea in most cases.')
|
||||
shared.gradio['min_length'] = gr.Slider(0, 2000, step=1, value=generate_params['min_length'], label='min_length', info='Minimum generation length in tokens.')
|
||||
shared.gradio['repetition_penalty'] = gr.Slider(1.0, 1.5, value=generate_params['repetition_penalty'],step=0.01,label='repetition_penalty')
|
||||
shared.gradio['encoder_repetition_penalty'] = gr.Slider(0.8, 1.5, value=generate_params['encoder_repetition_penalty'],step=0.01,label='encoder_repetition_penalty')
|
||||
shared.gradio['no_repeat_ngram_size'] = gr.Slider(0, 20, step=1, value=generate_params['no_repeat_ngram_size'], label='no_repeat_ngram_size')
|
||||
shared.gradio['min_length'] = gr.Slider(0, 2000, step=1, value=generate_params['min_length'] if shared.args.no_stream else 0, label='min_length', interactive=shared.args.no_stream)
|
||||
shared.gradio['do_sample'] = gr.Checkbox(value=generate_params['do_sample'], label='do_sample')
|
||||
with gr.Column():
|
||||
with gr.Box():
|
||||
gr.Markdown('Contrastive search')
|
||||
shared.gradio['penalty_alpha'] = gr.Slider(0, 5, value=generate_params['penalty_alpha'], label='penalty_alpha')
|
||||
|
||||
with gr.Box():
|
||||
gr.Markdown('Beam search (uses a lot of VRAM)')
|
||||
with gr.Row():
|
||||
@@ -273,22 +210,26 @@ def create_settings_menus(default_preset):
|
||||
with gr.Column():
|
||||
shared.gradio['length_penalty'] = gr.Slider(-5, 5, value=generate_params['length_penalty'], label='length_penalty')
|
||||
shared.gradio['early_stopping'] = gr.Checkbox(value=generate_params['early_stopping'], label='early_stopping')
|
||||
shared.gradio['add_bos_token'] = gr.Checkbox(value=shared.settings['add_bos_token'], label='Add the bos_token to the beginning of prompts', info='Disabling this can make the replies more creative.')
|
||||
|
||||
with gr.Row():
|
||||
shared.gradio['lora_menu'] = gr.Dropdown(choices=available_loras, value=shared.lora_name, label='LoRA')
|
||||
ui.create_refresh_button(shared.gradio['lora_menu'], lambda : None, lambda : {'choices': get_available_loras()}, 'refresh-button')
|
||||
|
||||
with gr.Accordion('Soft prompt', open=False):
|
||||
with gr.Row():
|
||||
shared.gradio['softprompts_menu'] = gr.Dropdown(choices=available_softprompts, value='None', label='Soft prompt')
|
||||
ui.create_refresh_button(shared.gradio['softprompts_menu'], lambda: None, lambda: {'choices': get_available_softprompts()}, 'refresh-button')
|
||||
ui.create_refresh_button(shared.gradio['softprompts_menu'], lambda : None, lambda : {'choices': get_available_softprompts()}, 'refresh-button')
|
||||
|
||||
gr.Markdown('Upload a soft prompt (.zip format):')
|
||||
with gr.Row():
|
||||
shared.gradio['upload_softprompt'] = gr.File(type='binary', file_types=['.zip'])
|
||||
|
||||
shared.gradio['model_menu'].change(load_model_wrapper, shared.gradio['model_menu'], shared.gradio['model_menu'], show_progress=True)
|
||||
shared.gradio['preset_menu'].change(load_preset_values, [shared.gradio[k] for k in ['preset_menu', 'generate_state']], [shared.gradio[k] for k in ['generate_state', 'do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'encoder_repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping']])
|
||||
shared.gradio['lora_menu'].change(load_lora_wrapper, shared.gradio['lora_menu'], shared.gradio['lora_menu'], show_progress=True)
|
||||
shared.gradio['softprompts_menu'].change(load_soft_prompt, shared.gradio['softprompts_menu'], shared.gradio['softprompts_menu'], show_progress=True)
|
||||
shared.gradio['upload_softprompt'].upload(upload_soft_prompt, shared.gradio['upload_softprompt'], shared.gradio['softprompts_menu'])
|
||||
|
||||
|
||||
def set_interface_arguments(interface_mode, extensions, bool_active):
|
||||
modes = ["default", "notebook", "chat", "cai_chat"]
|
||||
cmd_list = vars(shared.args)
|
||||
@@ -307,7 +248,6 @@ def set_interface_arguments(interface_mode, extensions, bool_active):
|
||||
|
||||
shared.need_restart = True
|
||||
|
||||
|
||||
available_models = get_available_models()
|
||||
available_presets = get_available_presets()
|
||||
available_characters = get_available_characters()
|
||||
@@ -341,7 +281,7 @@ else:
|
||||
for i, model in enumerate(available_models):
|
||||
print(f'{i+1}. {model}')
|
||||
print(f'\nWhich one do you want to load? 1-{len(available_models)}\n')
|
||||
i = int(input()) - 1
|
||||
i = int(input())-1
|
||||
print()
|
||||
shared.model_name = available_models[i]
|
||||
shared.model, shared.tokenizer = load_model(shared.model_name)
|
||||
@@ -354,27 +294,26 @@ if shared.lora_name != "None":
|
||||
default_text = load_prompt(shared.settings['lora_prompts'][next((k for k in shared.settings['lora_prompts'] if re.match(k.lower(), shared.lora_name.lower())), 'default')])
|
||||
else:
|
||||
default_text = load_prompt(shared.settings['prompts'][next((k for k in shared.settings['prompts'] if re.match(k.lower(), shared.model_name.lower())), 'default')])
|
||||
title = 'Text generation web UI'
|
||||
|
||||
title ='Text generation web UI'
|
||||
|
||||
def create_interface():
|
||||
|
||||
gen_events = []
|
||||
if shared.args.extensions is not None and len(shared.args.extensions) > 0:
|
||||
extensions_module.load_extensions()
|
||||
|
||||
with gr.Blocks(css=ui.css if not shared.is_chat() else ui.css + ui.chat_css, analytics_enabled=False, title=title) as shared.gradio['interface']:
|
||||
with gr.Blocks(css=ui.css if not shared.is_chat() else ui.css+ui.chat_css, analytics_enabled=False, title=title) as shared.gradio['interface']:
|
||||
if shared.is_chat():
|
||||
shared.gradio['Chat input'] = gr.State()
|
||||
with gr.Tab("Text generation", elem_id="main"):
|
||||
shared.gradio['display'] = gr.HTML(value=chat_html_wrapper(shared.history['visible'], shared.settings['name1'], shared.settings['name2'], 'cai-chat'))
|
||||
shared.gradio['textbox'] = gr.Textbox(label='Input')
|
||||
with gr.Row():
|
||||
shared.gradio['Generate'] = gr.Button('Generate', elem_id='Generate')
|
||||
shared.gradio['Generate'] = gr.Button('Generate')
|
||||
shared.gradio['Stop'] = gr.Button('Stop', elem_id="stop")
|
||||
with gr.Row():
|
||||
shared.gradio['Regenerate'] = gr.Button('Regenerate')
|
||||
shared.gradio['Continue'] = gr.Button('Continue')
|
||||
shared.gradio['Impersonate'] = gr.Button('Impersonate')
|
||||
shared.gradio['Regenerate'] = gr.Button('Regenerate')
|
||||
with gr.Row():
|
||||
shared.gradio['Copy last reply'] = gr.Button('Copy last reply')
|
||||
shared.gradio['Replace last reply'] = gr.Button('Replace last reply')
|
||||
@@ -385,7 +324,7 @@ def create_interface():
|
||||
shared.gradio['Clear history-cancel'] = gr.Button('Cancel', visible=False)
|
||||
|
||||
shared.gradio["Chat mode"] = gr.Radio(choices=["cai-chat", "chat", "instruct"], value="cai-chat", label="Mode")
|
||||
shared.gradio["Instruction templates"] = gr.Dropdown(choices=get_available_instruction_templates(), label="Instruction template", value="None", visible=False, info="Change this according to the model/LoRA that you are using.")
|
||||
shared.gradio["Instruction templates"] = gr.Dropdown(choices=get_available_instruction_templates(), label="Instruction template", value="None", visible=False)
|
||||
|
||||
with gr.Tab("Character", elem_id="chat-settings"):
|
||||
with gr.Row():
|
||||
@@ -400,7 +339,7 @@ def create_interface():
|
||||
shared.gradio['your_picture'] = gr.Image(label='Your picture', type="pil", value=Image.open(Path("cache/pfp_me.png")) if Path("cache/pfp_me.png").exists() else None)
|
||||
with gr.Row():
|
||||
shared.gradio['character_menu'] = gr.Dropdown(choices=available_characters, value='None', label='Character', elem_id='character-menu')
|
||||
ui.create_refresh_button(shared.gradio['character_menu'], lambda: None, lambda: {'choices': get_available_characters()}, 'refresh-button')
|
||||
ui.create_refresh_button(shared.gradio['character_menu'], lambda : None, lambda : {'choices': get_available_characters()}, 'refresh-button')
|
||||
|
||||
with gr.Row():
|
||||
with gr.Tab('Chat history'):
|
||||
@@ -440,72 +379,56 @@ def create_interface():
|
||||
create_settings_menus(default_preset)
|
||||
|
||||
shared.input_params = [shared.gradio[k] for k in ['Chat input', 'generate_state', 'name1', 'name2', 'context', 'Chat mode', 'end_of_turn']]
|
||||
clear_arr = [shared.gradio[k] for k in ['Clear history-confirm', 'Clear history', 'Clear history-cancel']]
|
||||
reload_inputs = [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']]
|
||||
|
||||
gen_events.append(shared.gradio['Generate'].click(
|
||||
lambda x: (x, ''), shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False).then(
|
||||
chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||
chat.save_history, shared.gradio['Chat mode'], None, show_progress=False)
|
||||
)
|
||||
|
||||
gen_events.append(shared.gradio['textbox'].submit(
|
||||
lambda x: (x, ''), shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False).then(
|
||||
chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||
chat.save_history, shared.gradio['Chat mode'], None, show_progress=False)
|
||||
)
|
||||
|
||||
gen_events.append(shared.gradio['Regenerate'].click(
|
||||
chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||
chat.save_history, shared.gradio['Chat mode'], None, show_progress=False)
|
||||
)
|
||||
|
||||
gen_events.append(shared.gradio['Continue'].click(
|
||||
chat.continue_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||
chat.save_history, shared.gradio['Chat mode'], None, show_progress=False)
|
||||
)
|
||||
|
||||
shared.gradio['Replace last reply'].click(
|
||||
chat.replace_last_reply, [shared.gradio[k] for k in ['textbox', 'name1', 'name2', 'Chat mode']], shared.gradio['display'], show_progress=shared.args.no_stream).then(
|
||||
lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False).then(
|
||||
chat.save_history, shared.gradio['Chat mode'], None, show_progress=False)
|
||||
|
||||
shared.gradio['Clear history-confirm'].click(
|
||||
lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr).then(
|
||||
chat.clear_chat_log, [shared.gradio[k] for k in ['name1', 'name2', 'greeting', 'Chat mode']], shared.gradio['display']).then(
|
||||
chat.save_history, shared.gradio['Chat mode'], None, show_progress=False)
|
||||
|
||||
shared.gradio['Stop'].click(
|
||||
stop_everything_event, None, None, queue=False, cancels=gen_events if shared.args.no_stream else None).then(
|
||||
chat.redraw_html, reload_inputs, shared.gradio['display'])
|
||||
|
||||
shared.gradio['Chat mode'].change(
|
||||
lambda x: gr.update(visible=x == 'instruct'), shared.gradio['Chat mode'], shared.gradio['Instruction templates']).then(
|
||||
lambda x: gr.update(interactive=x != 'instruct'), shared.gradio['Chat mode'], shared.gradio['character_menu']).then(
|
||||
chat.redraw_html, reload_inputs, shared.gradio['display'])
|
||||
|
||||
shared.gradio['Instruction templates'].change(
|
||||
lambda character, name1, name2, mode: chat.load_character(character, name1, name2, mode), [shared.gradio[k] for k in ['Instruction templates', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']]).then(
|
||||
chat.redraw_html, reload_inputs, shared.gradio['display'])
|
||||
|
||||
shared.gradio['upload_chat_history'].upload(
|
||||
chat.load_history, [shared.gradio[k] for k in ['upload_chat_history', 'name1', 'name2']], None).then(
|
||||
chat.redraw_html, reload_inputs, shared.gradio['display'])
|
||||
def set_chat_input(textbox):
|
||||
return textbox, ""
|
||||
|
||||
gen_events.append(shared.gradio['Generate'].click(set_chat_input, shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False))
|
||||
gen_events.append(shared.gradio['Generate'].click(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
|
||||
gen_events.append(shared.gradio['textbox'].submit(set_chat_input, shared.gradio['textbox'], [shared.gradio['Chat input'], shared.gradio['textbox']], show_progress=False))
|
||||
gen_events.append(shared.gradio['textbox'].submit(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
|
||||
gen_events.append(shared.gradio['Regenerate'].click(chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
|
||||
gen_events.append(shared.gradio['Impersonate'].click(chat.impersonate_wrapper, shared.input_params, shared.gradio['textbox'], show_progress=shared.args.no_stream))
|
||||
shared.gradio['Copy last reply'].click(chat.send_last_reply_to_input, None, shared.gradio['textbox'], show_progress=shared.args.no_stream)
|
||||
shared.gradio['Clear history'].click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, clear_arr)
|
||||
shared.gradio['Clear history-cancel'].click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr)
|
||||
shared.gradio['Stop'].click(stop_everything_event, [], [], queue=False, cancels=gen_events if shared.args.no_stream else None)
|
||||
|
||||
shared.gradio['Copy last reply'].click(chat.send_last_reply_to_input, [], shared.gradio['textbox'], show_progress=shared.args.no_stream)
|
||||
shared.gradio['Replace last reply'].click(chat.replace_last_reply, [shared.gradio[k] for k in ['textbox', 'name1', 'name2', 'Chat mode']], shared.gradio['display'], show_progress=shared.args.no_stream)
|
||||
|
||||
# Clear history with confirmation
|
||||
clear_arr = [shared.gradio[k] for k in ['Clear history-confirm', 'Clear history', 'Clear history-cancel']]
|
||||
shared.gradio['Clear history'].click(lambda :[gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, clear_arr)
|
||||
shared.gradio['Clear history-confirm'].click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr)
|
||||
shared.gradio['Clear history-confirm'].click(chat.clear_chat_log, [shared.gradio[k] for k in ['name1', 'name2', 'greeting', 'Chat mode']], shared.gradio['display'])
|
||||
shared.gradio['Clear history-cancel'].click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, clear_arr)
|
||||
shared.gradio['Chat mode'].change(lambda x : gr.update(visible= x=='instruct'), shared.gradio['Chat mode'], shared.gradio['Instruction templates'])
|
||||
|
||||
shared.gradio['Remove last'].click(chat.remove_last_message, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], [shared.gradio['display'], shared.gradio['textbox']], show_progress=False)
|
||||
shared.gradio['download_button'].click(lambda x: chat.save_history(x, timestamp=True), shared.gradio['Chat mode'], shared.gradio['download'])
|
||||
shared.gradio['download_button'].click(chat.save_history, inputs=[], outputs=[shared.gradio['download']])
|
||||
shared.gradio['Upload character'].click(chat.upload_character, [shared.gradio['upload_json'], shared.gradio['upload_img_bot']], [shared.gradio['character_menu']])
|
||||
|
||||
# Clearing stuff and saving the history
|
||||
for i in ['Generate', 'Regenerate', 'Replace last reply']:
|
||||
shared.gradio[i].click(lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False)
|
||||
shared.gradio[i].click(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
shared.gradio['Clear history-confirm'].click(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
shared.gradio['textbox'].submit(lambda x: '', shared.gradio['textbox'], shared.gradio['textbox'], show_progress=False)
|
||||
shared.gradio['textbox'].submit(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
|
||||
|
||||
shared.gradio['character_menu'].change(chat.load_character, [shared.gradio[k] for k in ['character_menu', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']])
|
||||
shared.gradio['Instruction templates'].change(lambda character, name1, name2, mode: chat.load_character(character, name1, name2, mode), [shared.gradio[k] for k in ['Instruction templates', 'name1', 'name2', 'Chat mode']], [shared.gradio[k] for k in ['name1', 'name2', 'character_picture', 'greeting', 'context', 'end_of_turn', 'display']])
|
||||
shared.gradio['upload_chat_history'].upload(chat.load_history, [shared.gradio[k] for k in ['upload_chat_history', 'name1', 'name2']], [])
|
||||
shared.gradio['upload_img_tavern'].upload(chat.upload_tavern_character, [shared.gradio['upload_img_tavern'], shared.gradio['name1'], shared.gradio['name2']], [shared.gradio['character_menu']])
|
||||
shared.gradio['your_picture'].change(chat.upload_your_profile_picture, [shared.gradio[k] for k in ['your_picture', 'name1', 'name2', 'Chat mode']], shared.gradio['display'])
|
||||
|
||||
reload_inputs = [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']]
|
||||
shared.gradio['upload_chat_history'].upload(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||
shared.gradio['Stop'].click(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||
shared.gradio['Instruction templates'].change(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||
shared.gradio['Chat mode'].change(chat.redraw_html, reload_inputs, [shared.gradio['display']])
|
||||
|
||||
shared.gradio['interface'].load(None, None, None, _js=f"() => {{{ui.main_js+ui.chat_js}}}")
|
||||
shared.gradio['interface'].load(chat.load_default_history, [shared.gradio[k] for k in ['name1', 'name2']], None)
|
||||
shared.gradio['interface'].load(chat.redraw_html, reload_inputs, shared.gradio['display'], show_progress=True)
|
||||
shared.gradio['interface'].load(lambda : chat.load_default_history(shared.settings['name1'], shared.settings['name2']), None, None)
|
||||
shared.gradio['interface'].load(chat.redraw_html, reload_inputs, [shared.gradio['display']], show_progress=True)
|
||||
|
||||
elif shared.args.notebook:
|
||||
with gr.Tab("Text generation", elem_id="main"):
|
||||
@@ -539,7 +462,7 @@ def create_interface():
|
||||
output_params = [shared.gradio[k] for k in ['textbox', 'markdown', 'html']]
|
||||
gen_events.append(shared.gradio['Generate'].click(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream))
|
||||
gen_events.append(shared.gradio['textbox'].submit(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream))
|
||||
shared.gradio['Stop'].click(stop_everything_event, None, None, queue=False, cancels=gen_events if shared.args.no_stream else None)
|
||||
shared.gradio['Stop'].click(stop_everything_event, [], [], queue=False, cancels=gen_events if shared.args.no_stream else None)
|
||||
shared.gradio['interface'].load(None, None, None, _js=f"() => {{{ui.main_js}}}")
|
||||
|
||||
else:
|
||||
@@ -573,12 +496,9 @@ def create_interface():
|
||||
gen_events.append(shared.gradio['Generate'].click(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream))
|
||||
gen_events.append(shared.gradio['textbox'].submit(generate_reply, shared.input_params, output_params, show_progress=shared.args.no_stream))
|
||||
gen_events.append(shared.gradio['Continue'].click(generate_reply, [shared.gradio['output_textbox']] + shared.input_params[1:], output_params, show_progress=shared.args.no_stream))
|
||||
shared.gradio['Stop'].click(stop_everything_event, None, None, queue=False, cancels=gen_events if shared.args.no_stream else None)
|
||||
shared.gradio['Stop'].click(stop_everything_event, [], [], queue=False, cancels=gen_events if shared.args.no_stream else None)
|
||||
shared.gradio['interface'].load(None, None, None, _js=f"() => {{{ui.main_js}}}")
|
||||
|
||||
with gr.Tab("Model", elem_id="model-tab"):
|
||||
create_model_menus()
|
||||
|
||||
with gr.Tab("Training", elem_id="training-tab"):
|
||||
training.create_train_interface()
|
||||
|
||||
@@ -592,17 +512,16 @@ def create_interface():
|
||||
cmd_list = vars(shared.args)
|
||||
bool_list = [k for k in cmd_list if type(cmd_list[k]) is bool and k not in modes]
|
||||
bool_active = [k for k in bool_list if vars(shared.args)[k]]
|
||||
#int_list = [k for k in cmd_list if type(k) is int]
|
||||
|
||||
gr.Markdown("*Experimental*")
|
||||
shared.gradio['interface_modes_menu'] = gr.Dropdown(choices=modes, value=current_mode, label="Mode")
|
||||
shared.gradio['extensions_menu'] = gr.CheckboxGroup(choices=get_available_extensions(), value=shared.args.extensions, label="Available extensions")
|
||||
shared.gradio['bool_menu'] = gr.CheckboxGroup(choices=bool_list, value=bool_active, label="Boolean command-line flags")
|
||||
shared.gradio['reset_interface'] = gr.Button("Apply and restart the interface")
|
||||
shared.gradio['reset_interface'] = gr.Button("Apply and restart the interface", type="primary")
|
||||
|
||||
# Reset interface event
|
||||
shared.gradio['reset_interface'].click(
|
||||
set_interface_arguments, [shared.gradio[k] for k in ['interface_modes_menu', 'extensions_menu', 'bool_menu']], None).then(
|
||||
lambda: None, None, None, _js='() => {document.body.innerHTML=\'<h1 style="font-family:monospace;margin-top:20%;color:lightgray;text-align:center;">Reloading...</h1>\'; setTimeout(function(){location.reload()},2500); return []}')
|
||||
shared.gradio['reset_interface'].click(set_interface_arguments, [shared.gradio[k] for k in ['interface_modes_menu', 'extensions_menu', 'bool_menu']], None)
|
||||
shared.gradio['reset_interface'].click(lambda : None, None, None, _js='() => {document.body.innerHTML=\'<h1 style="font-family:monospace;margin-top:20%;color:lightgray;text-align:center;">Reloading...</h1>\'; setTimeout(function(){location.reload()},2500); return []}')
|
||||
|
||||
if shared.args.extensions is not None:
|
||||
extensions_module.create_extensions_block()
|
||||
@@ -611,7 +530,7 @@ def create_interface():
|
||||
d[key] = value
|
||||
return d
|
||||
|
||||
for k in ['do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'encoder_repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping', 'add_bos_token', 'max_new_tokens', 'seed', 'stop_at_newline', 'chat_prompt_size_slider', 'chat_generation_attempts']:
|
||||
for k in ['do_sample', 'temperature', 'top_p', 'typical_p', 'repetition_penalty', 'encoder_repetition_penalty', 'top_k', 'min_length', 'no_repeat_ngram_size', 'num_beams', 'penalty_alpha', 'length_penalty', 'early_stopping', 'max_new_tokens', 'seed', 'stop_at_newline', 'chat_prompt_size_slider', 'chat_generation_attempts']:
|
||||
if k not in shared.gradio:
|
||||
continue
|
||||
if type(shared.gradio[k]) in [gr.Checkbox, gr.Number]:
|
||||
@@ -638,7 +557,6 @@ def create_interface():
|
||||
else:
|
||||
shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_port=shared.args.listen_port, inbrowser=shared.args.auto_launch, auth=auth)
|
||||
|
||||
|
||||
create_interface()
|
||||
|
||||
while True:
|
||||
|
||||
@@ -7,9 +7,7 @@
|
||||
"name2": "Assistant",
|
||||
"context": "This is a conversation with your Assistant. The Assistant is very helpful and is eager to chat with you and answer your questions.",
|
||||
"greeting": "Hello there!",
|
||||
"end_of_turn": "",
|
||||
"stop_at_newline": false,
|
||||
"add_bos_token": true,
|
||||
"chat_prompt_size": 2048,
|
||||
"chat_prompt_size_min": 0,
|
||||
"chat_prompt_size_max": 2048,
|
||||
@@ -21,8 +19,7 @@
|
||||
"gallery"
|
||||
],
|
||||
"presets": {
|
||||
"default": "Default",
|
||||
".*(alpaca|llama)": "LLaMA-Precise",
|
||||
"default": "NovelAI-Sphinx Moth",
|
||||
".*pygmalion": "NovelAI-Storywriter",
|
||||
".*RWKV": "Naive"
|
||||
},
|
||||
|
||||
Reference in New Issue
Block a user